Я посмотрела, как тестируют поиск начинающие тестировщики, и решила написать этот чит-лист проверок. Это такая серебряная пуля, которую можно применить на любом проекте, лишь немного варьируя под себя, под свой проект.

Поиск — он же есть практически в каждой системе. Поэтому здорово, когда есть шпаргалка «какие вопросы задать аналитику» и «какие проверки провести». Именно это мы в статье и обсудим. Сначала я дам чек-лист, а потом разберу каждый пункт отдельно.
Ссылка на ХАБР (там кликабельное оглавление)
Что надо узнать
По каким полям поиск должен работать / по каким нет
Ищет по включению или полному соответствию?
Регистрозависимый ли поиск?
Какая максимальная длина поисковой строки?
А если длина превышена, запрос обрезается?
Как работает поиск при пустом запросе?
Что надо проверить
Повторю список, немного прокомментировав каждый пункт, чтобы вы могли пользоваться именно им в дальнейшем. Что надо проверить, тестируя поиск:
Поиск ищет по всем полям, указанным в ТЗ
Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
Релевантность выдачи — то, что я ищу, в начале списка, или в конце?
Учитывается ли контекст поиска — ищу я по всему сайту или только разделу игрушек
Регистронезависимость поиска — найдет ли «Платье», если я ввела «платье»?
Ищет ли по включению или полному соответствию — «ту» найдет мне «туфли»?
Найдет ли 2 слова из одного поля? В любом порядке введенные?
Найдет ли 2 слова из разных полей?
Ошибка в вводе (исправляются ли опечатки, ищет ли похожее)
Исправляет ли система неправильную раскладку?
Ищет ли на разных языках? А если сразу на двух попробовать?
Поиск со спецсимволами работает?
А с эмоджи? Не упадет система при вводе какашки?
Тримаются ли открывающие и закрывающие пробелы
Пустое поле / только пробелы в поле
Нижнюю границу (от скольких символов ищет)
Верхнюю произвольную границу — указанную в ТЗ
Верхнюю границу на выходе
Поиск технологической границы — ввести «войну и мир», 100 млн символов
Давайте пройдемся по каждому пункту и выясним, как и зачем его проверять.
1. Поиск ищет по всем полям, указанным в ТЗ
Вроде бы капитан очевидность, но с чего только новички не начинают свой чек-лист:
Оставить поле пустым
Вбить кириллицу / латиницу
Большую строку
Всяко потыкать поиск по названию (а если часть названия указать, а если с опечаткой, а если...)
Если надо выбирать, то последний вариант выглядит наиболее логичным. Он по крайней мере не абстрактная серебряная пуля про любое текстовое поле. Он про поиск.
Но ведь чтобы всяко-разно издеваться над названием, надо сначала убедиться, что по названию вообще ищет, верно? Так что пишем в названии слово «Тест» (или любое другое, но одно, без спецсимволов и прочего), его же вводим в строку поиска. Так мы понимаем, что поиск по названию в принципе работает. Значит, можно будет дальше над ним изгаляться =)
Но сначала надо проверить основное — то, что поиск вообще работает. Что он ищет по всем тем полям, по которым должен.

Иначе сами представьте, идет у нас чек-лист на 30 проверок по названию, а потом уже «что поиск работает по описанию, категории товара, бренду...». А времени на тестирование нет, и выделяется буквально 5-10 минут.
В итоге тестировщик провел первые 20 тестов и гордо говорит:
— Всё отлично! Поиск работает! А если всякую чухню в него вбить, не падает!
При этом поиск работает по 1 полю из 10 обязательных. И пользователи пытаются искать, а у них ничего не получается, потому что ищут не по названию. Нехорошо…

В любом чек-листе надо думать о приоритетах. Сначала — самое важное. Как в чек-листе в целом, так и внутри каждого блока проверок, постепенно идем от важного к неважному. От позитива к негативу.
Чтобы при ограниченном времени не пытаться в спешке понять, что в чек-листе важно, прыгая глазами туда-сюда и ища эти пункты.
А что самое важное в поиске? Для этого думаем, зачем его вообще делают. Чтобы искать. По чему? По каким-то полям / признакам. По каким? Узнаем и проверяем, ищет он по ним или нет.
2. Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
Если прошлый пункт ещё очевиден новичкам, то этот не особо. Поэтому давайте сначала подумаем — а зачем тестировать то, что поиск не работает по полям, по которым не должен? Может, ну их, эти поля? Не должен же искать, чего проверять то?
А теперь представьте себе ситуации:
1. Я ищу в интернет-магазине «белая майка», а система вываливает всё, что угодно:
Черная майка
Зеленый топ
Красные штаны
…
И если разобраться, то найдем слова «белая» и «майка» где-то внутри этих товаров. Например, в комментариях.
2. Я операционист банка. Пришла клиентка «Ольга Гагарина», я ищу её в системе, а в ответ получаю:
Ольга Морозова (у которой адрес прописки на ул Гагарина)
Иван Иванов (жена Ольга, в адресе тоже есть Гагарина)
Петр Забубенов (в комментарии к адресу «арендодатель Ольга», в любимых певицах Гагарина)
…

Ведь не зря же делают поиск по конкретным полям, а не «ищи по всему, что видишь». Как раз для того, чтобы результат был более релевантным. И если не тестировать, что поиск НЕ ищет там, где не должен, то в поисковую выборку может попасть вообще не то, что хотелось.
Поэтому проверять «поиск по полю НЕ ищет» тоже надо. А как? Вот тестируют у меня студенты Folks. Читаем ТЗ:
Фолкс найдет человека по следующим признакам: ФИО, предпочтительному имени, дате рождения(дд.мм.гггг), компании, модели девайса, его OS, автору изменений
Первая попытка — проверяют только перечисленные поля в чек-листе. Убеждаются, что поиск по ним работает. Обсуждаем, зачем тестировать «негатив», выясняем. Следующая попытка — проводится один дополнительный тест, что по одному из оставшихся полей карточки поиск НЕ работает. И всё.
Обсуждаем на кошках: допустим, в системе есть 100 полей. Поиск работает только по 10 из них. Что проверяем?
— Что по каждому из этих полей ищет. И одно любое другое, что по нему НЕ ищет.
Моя коллега Ольга Алифанова придумала такую аналогию для этой ситуации:
У нас огромный гипермаркет, в нем сто отделов
В десяти из этих отделов продавщицы Клава, Маня, Муся, Света, Ира, Ната, Дина, Раиса, Тамара и Галя никогда не должны обвешивать никого. В 90 оставшихся отделах продавщицы обвешивают всех.
Достаточно ли нам убедиться, что Муся дает точный вес, чтобы сказать, что Света и Раиса тоже не обманывают покупателей?

Если мы проверили одно поле, мы знаем ровно то, что именно по этому полю система НЕ ищет. Но мы ничего не знаем про оставшиеся 89 полей. И не узнаем, пока не проверим.
А проверять надо, потому что иначе мы рискуем получить нерелевантный поиск, который работает по абсолютно рандомным полям системы.
Но тогда возникает другой вопрос. Сколько это тестов?
Поиск ищет по всем полям, указанным в ТЗ
Поиск НЕ ищет по тем полям, которые НЕ указаны в ТЗ
Нужно ли нам писать отдельный тест на каждое поле? Или их можно объединить? Не получится ли кейс «я надену всё лучшее сразу» и при падении теста будет совершенно непонятно, на чем именно сломалось?

См также:
В тестировании всегда начинаем с простого — чем плох принцип «надену всё лучшее сразу»
Смотрите, допустим, что у нас по полю с именем искать система должна, а по фамилии — не должна. Я пишу тест:
В строку поиска вбить: Тест
В системе подготовить карточки с данными:
1. Имя = Тест
2. Фамилия = Тест
ОР: 1
Давайте предположим, что в системе баг и по фамилии она тоже ищет. Какой будет ФР?
ФР: 1, 2
Вернулись обе карточки. Можно ли на основании этого сделать вывод, из-за чего именно поиск сломался? Из-за какого конкретно поля? Можно! Мы четко понимаем из такого ФР, что:
Поиск по имени работает правильно
А вот с фамилией косяк
И наоборот, если у нас будет такой результат:
ФР: (пусто)
Мы тоже вполне четко понимаем, что:
С именем косяк
Фамилия работает как надо
Получается, мы можем объединить тесты без потери простоты локализации при падении! Даже если полей будет 100, а не 2.

А дальше уже встает вопрос простоты проведения =) Вернемся к примеру про 100 полей, из которых поиск работает только по 10.
Вот смотрите, если мы делаем автоматизированный тест, то делаем «сразу хорошо». Один раз заполнили 100 карточек, в каждой 1 поле (каждый раз разное).
А вот если мы проводим тест вручную, то тут надо понимать, что заполнение каждой карточки — это затраты времени. Нажал «создать», заполнил поле, нажал «Сохранить» и система чуток подумала при сохранении. И так 100 раз? Грустновато получается.

Вообще в этом случае идеальный вариант — полуавтоматизация. Например, REST-метод создания карточки. Тогда создали в постмане коллекцию для создания 100 карточек один раз — а потом один щелчок кнопки, и все карточки готовы!
Или может, разработчик поможет написать утилитку для заполнения базы. Вот как пример у меня было на одном из проектов: заполняешь табличку экселя значениями, одна команда — и они уже в базе! И снова всё просто. Один раз табличку подготовили, потом используем.
А вот если у нас только графический интерфейс, тогда уже начинаем думать, что можно совместить без потери «качества».
Можно ли ввести искомое слово во все 10 полей одной карточки? Нет, потому что когда система её найдет, мы не будем знать, по какому из 10 полей она сработала. И информацию от такого теста мы получим лишь “по какому-то полю из 10 обязательных поиск работает”. Не совсем то, что надо. Значит, позитив объединить нельзя, создаем 10 карточек.
А как насчет негатива? Поиск НЕ должен сработать по 90 полям. Значит, мы можем заполнить все 90 полей одним значением в одной карточке. И поискать по нему. В идеале система ничего не найдет.

Конечно, если в системе есть баг и карточка нашлась, ошибку придется локализовывать. И тогда уже или заполнять 90 разных карточек, или использовать метод бисеционного деления.
А как правильно заполнить наши поля? Каким-то одним значением. Оно должно быть простое, без излишеств, без принципа «надену всё лучшее сразу». То есть не надо сразу класть туда спецсимволы, эмоджи, разные алфавиты и регистры, комбинацию слов через пробел… Написали везде «тест» или «котик», и всё.
Потому что сейчас мы проверяем самое важное — что поиск вообще работает. А вот как он работает и обрабатывает всяко-разный ввод — проверим чуть позже. А иначе если поиск не сработает на «%#$**», как понять, он вообще не работает по полю, или не ищет спецсимволы?

3. Релевантность выдачи
Здесь важно проверить приоритет поисковой выдачи. Понятно, что туда может попасть что-то «не то». Чем больше у нас данных и чем больше полей, по которым поиск возможен, тем больше вариантов на каждый запрос.
Вот, допустим, пытаюсь я найти однотонное платье в интернет-магазине. Что я могу задать в поиске? «Желтое платье». Что я получаю в выборке?
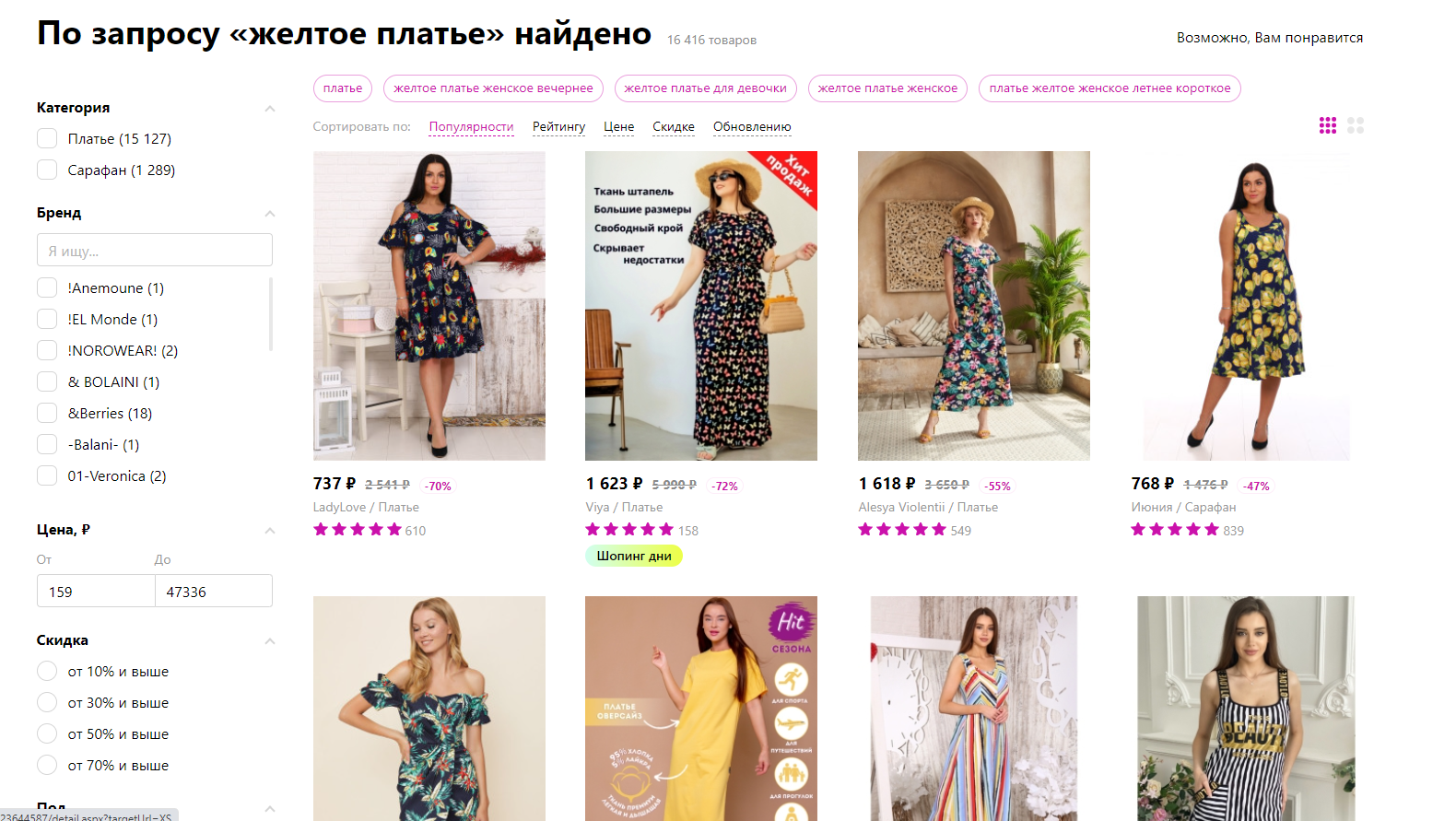
Целиком желтое платье на ШЕСТОМ месте. После 5 черных с вкраплениями желтого цвета.
С одной стороны, это логично. Ведь на других платьях желтый цвет тоже есть, поэтому его добавили в параметр «цвета». Ищем по параметрам:
Платье — да, тут платья
Желтый цвет — да, в блоке «цвета» есть слово «желтый» у каждого.
И как раз в силу большого ассортимента товаров мы получаем то, что получаем. Можно ли как-то на эту выборку повлиять?
Можно. Причем можно даже разные варианты придумать:
Можно добавить в систему галочку «однотонная вещь». И проставлять её при заполнении товаров. А потом уже по запросу вещи конкретного цвета выводить сначала вещи с этой галочкой, а потом уже все остальные.
При этом можно даже в фильтры вывести такую галку, чтобы пользователь мог выбрать “только однотонные”, и получить только вещи нужного ему цвета.
Можно фильтр настроить так:
Сначала вещи, у которых только один цвет
Потом все остальные (многоцветные)
В этом случае также можно сделать галку для пользователя “только однотонные”, которая будет выводить только вещи, в которых указан один цвет.
Можно при заполнении цветов вещи добавить галку «основной», если они выбираются из списка. Или, если их вводят вручную (что вряд ли) ориентироваться на порядок цветов. Какой идет первым — он приоритетный.
И тогда уже при выдаче результатов сначала отдаем вещи, у которых запрошенный пользователем — приоритетный.
А вот другой пример. Исходный запрос — «красная майка женская»:

Что вернула система:
Черная майка
Мужская майка
Розовая с белым
Белая майка
...
А то, что нам нужно, аж на 8-ом месте. Почему так? А снова приоритеты. Где-то мелькнуло слово «красный», вон на мужских майках то каемка красная, то майка. Где-то просто ошиблись цветом при заполнении данных (и такое бывает), где-то в комментариях или другом описании было написано ключевое слово (что-то типа «подойдет и мужчинам, и женщинам, унисекс!»).
Но в результате — нерелевантная выборка. И если большой интернет-магазин с его оборотами может себе это позволить (и так найдут), то маленький, пытающийся завоевать доверие пользователей — нет. Впрочем, это уже выбор хозяина продукта.
Тут хотелось бы добавить, что поиск может быть не только в интернет-магазине. Искать можно среди данных: ФИО, адресов, телефонов... Например, если у нас система с клиентскими данными типа Users. Или подсказки Дадаты, ведь они работают по своим справочникам, но приоритезируют информацию:

Имена бывают самые разные, но если вместо Александра и Алексея система предложит Алладина, Алана и Алмаза, то толку от такой системы? Проще руками ввести...
4. Контекст поиска
Откуда я вызываю поиск? С главной страницы сайта или из конкретного раздела?
Скажем, если на Озоне попробовать поискать «котенок» на главной странице, он поищет везде: в книжках, игрушках, чашках, воздушных шариках...
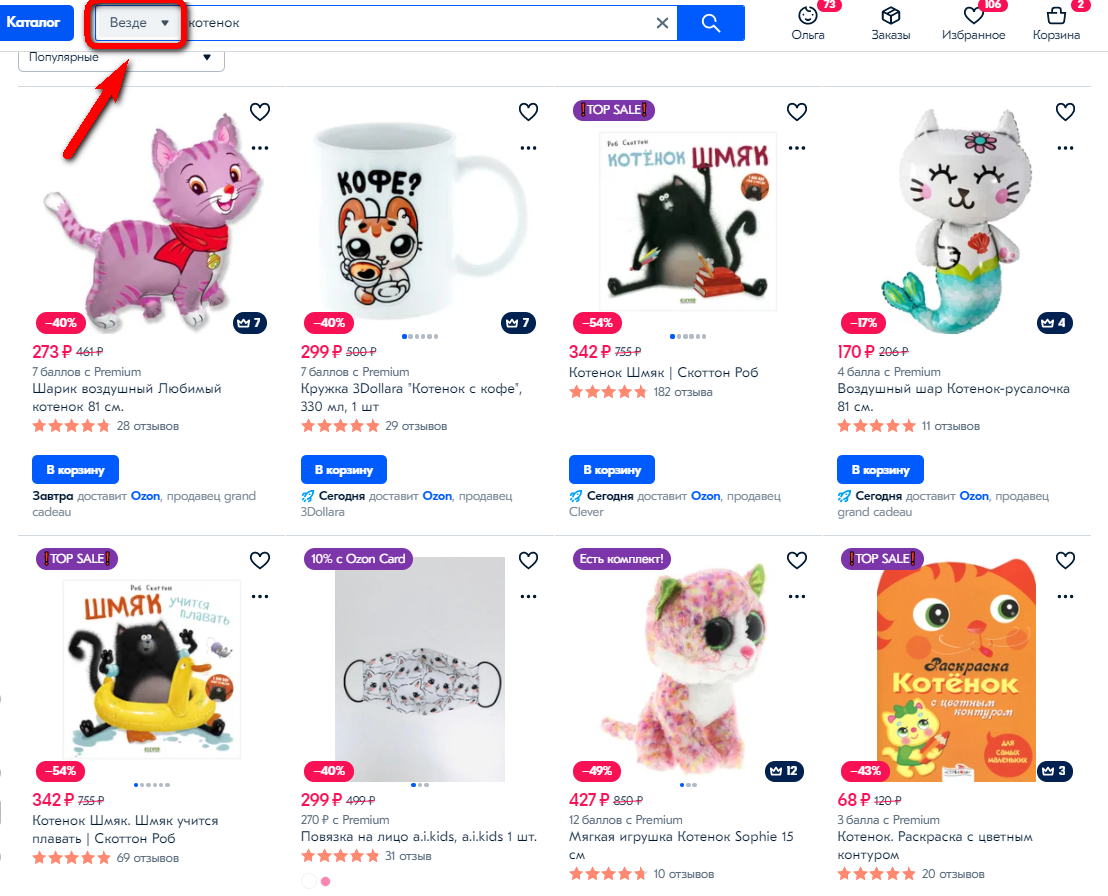
А вот если я буду искать в разделе книг, то буду ожидать только книги про котят, не игрушки:

В интернет-магазинах обычно куча разных товаров, поэтому контекст поиска очень важен, чтобы выдавать релевантные товары.
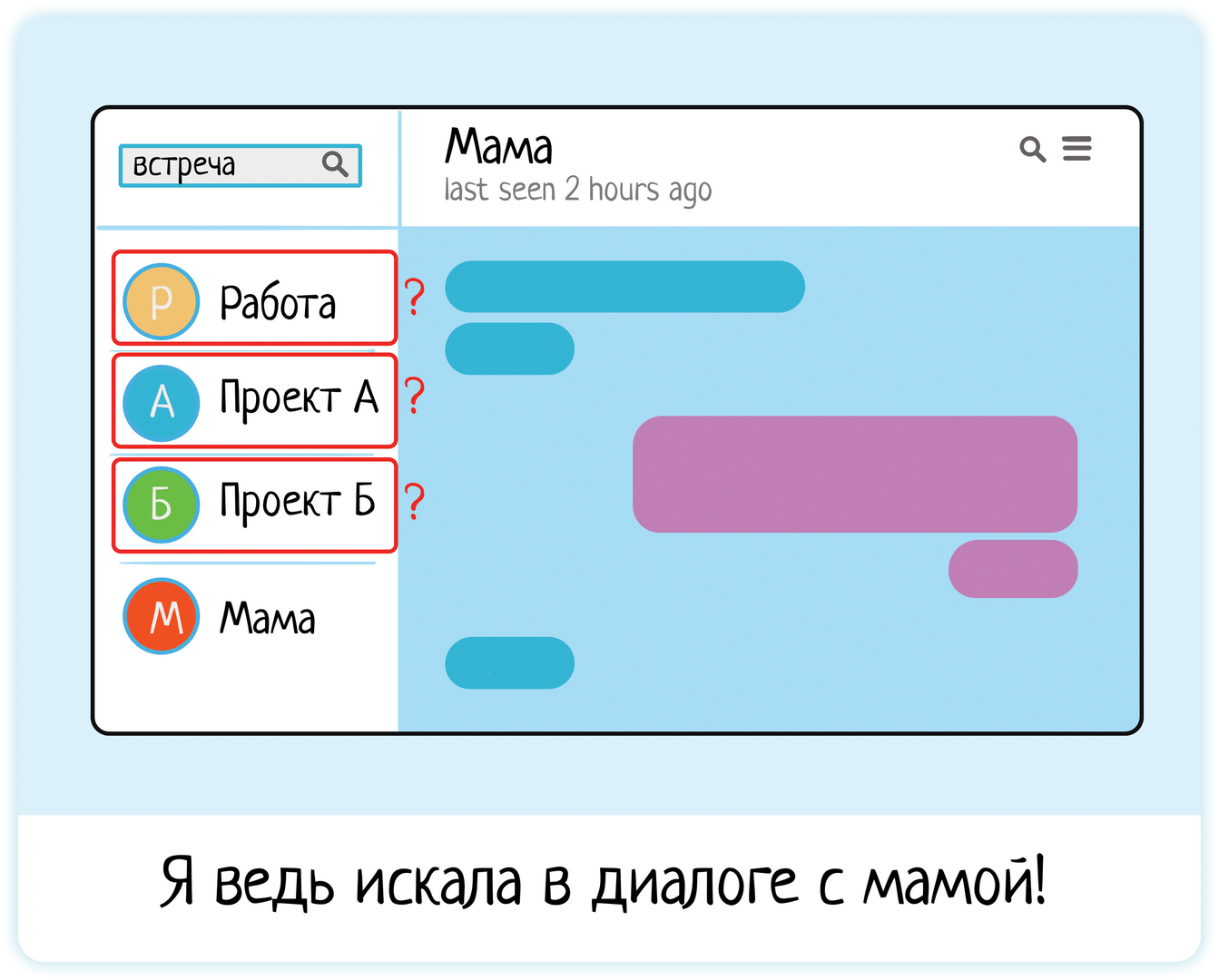
А ещё контекст очень важен в мессенджерах. Искать вообще везде, во всех 100500 чатах, или только в одном? Будет очень плохо, если я запущу поиск по диалогу с мамой, а система выдаст мне кучу рабочих чатиков, где нашла совпадение…
5. Регистронезависимость поиска
Обычно поиск регистронезависимый, и это логично. Представьте, что я ввожу:
Женское платье
А система ничего не находит, ведь у неё есть только «Платье» (первая заглавная, а у нас в запросе — нет)… Но пользователь же не в курсе, что надо немного изменить запрос, он будет думать, что платья тут просто не продаются…
Так что проверяем:
нижний регистр
ВЕРХНИЙ РЕГИСТР
ЗоЛоТую СеРеДиНу
.
6. Ищет ли по включению или полному соответствию
Поиск по включению — это когда можно ввести только часть слова. Например, «ко» вместо «котик». Это очень удобно во всяких чатах. Вот, например, я помню, что Ольга рассказывала историю про баг, связанный с кораблем. Но в каком падеже она говорила?
На корабле…
У корабля…
Есть корабль…
Если поиск работает по полному совпадению, то нужно перебирать все падежи. Если он работает по включению, мне достаточно написать «корабл».
Бывает, что сам поиск работает по полному совпадению, но при вводе подсказывает варианты:
Ту → туфли / тушь / туника

При этом если выбрал подсказку — показались товары. А если не выбрал, то сам себе злобная чебурашка.

Впрочем, некоторые магазины всё равно предлагают товары. Или которые включают в себя введенный текст, или какие-то вариации (Озон мне на «ту» выдал товары с «Two» в названии!)
В любом случае, нужно уточнить — как должно работать? А потом проверить:
Поиск по полному соответствию в одном слове
Поиск по частичному соответствию в одном слове — совпадение в начале слова / середине / конце (вспоминаем про классы эквивалентности и граничные значения)
.
7. Два слова из одного поля
А что будет, если у нас не одно слово, а два или более? Причем 2 слова у нас может быть:
В искомом поле
В поисковом запросе
И это будут разные тесты! Например, название товара: «Игровой набор». Тесты при этом:
Игровой → то есть в поле несколько слов, а мы ввели одно из них, найдётся?
Игровой набор → в поиске тоже несколько слов
Но что будет, если в поиске мы изменим порядок слов?
Набор игровой → найдется ли он в таком формате? Или нужно прям четкое совпадение?

8. Два слова из разных полей
Если мы проверяем несколько слов в поиске, то тут тоже возможны варианты:
Они все из разных полей — например, мы ищем по цвету + названию + полу: «красная майка женская».
Они из одного поля — как выше с игровым набором. И в этом случае намного интереснее изменить порядок слов и проверить поведение системы =)
Важно понимать, что это разные тесты. И стоит проверить и тот вариант, и другой.
.
9. Опечатки
Как система работает с опечатками? Найдет ли похожее слово?
Краный галстук → Красный галстук
Если система работает с опечатками, то как:
1 неправильную букву исправит / 2 и более
1 пропущенную букву исправит / 2 и более
Это, конечно, зависит от длины искомого слова, но тогда исправляются ли опечатки в коротких словах? Тут, главное, не увлечься, и не побежать ставить баг «система не исправила хлеб на пиво» =))

10. Неправильная раскладка
Типичный пример опечатки — пользователь забыл изменить раскладку на клавиатуре и напечатал английскими символами русский текст. Ищем «котик» но вводим «rjnbr».
Озон понимает, что мы ошиблись и ненавязчиво исправляет ошибку, подсказывая варианты по котикам:

Если нажать энтер, то увидим, что система исправила раскладку прямо в поисковой строке, но на всякий случай уточняет, правильно ли сделала:
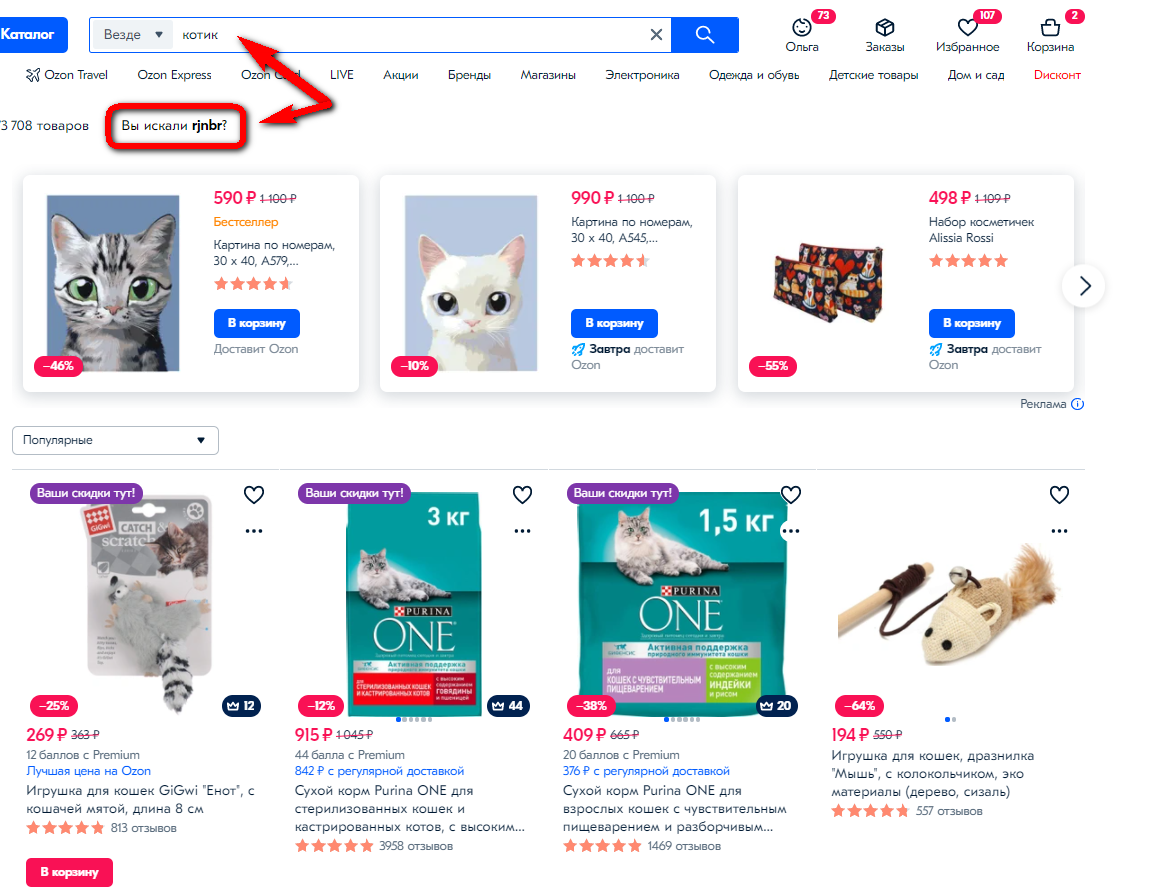
Это — хороший тон. Если система русскоязычная и пользователь ввел данные на английском, по которым ничего не ищется, надо проверить — не забыл ли он переключить раскладку? Если по переключенной раскладке поиск работает, показываем эти результаты.
Всегда лучше ненавязчиво исправить ошибку пользователя, чем гневно тыкать ему под нос «По такому запросу ничего не найдено!!»
.
11. Другой язык
Что, если в системе есть данные и на русском, и на английском? Или даже смешанный вариант: «Сухой корм Purina ONE». Найдет ли система и по русскому алфавиту, и по английскому?
А ещё интересный кейс, если в системе можно изменить язык! Что будет, если я изменю язык сайта на английский, а поищу по русскому названию, или наоборот?
12. Спецсимволы
Это стандартная серебряная пуля для всех текстовых полей:
Русский алфавит
Английский
Спецсимволы
Эмоджи
Перемешал
И поэтому приоритет у таких проверок не супер-важный. Ведь проверить “английский, русский, спецсимволы, перемешал” может любой человек, даже робот. А тестировщик отталкивается от того, что он вообще тестирует. Что это за поле, для чего оно нужно? Сначала особенность приложения, потом серебряная пуля.
Но проверять этот мини чек-лист для любого текстового поля тоже надо. Ведь нам надо предоставить информацию о том, как система себя поведет в том или ином случае. А спецсимволы попасть в поле вполне себе могут, причем по разным причинам.
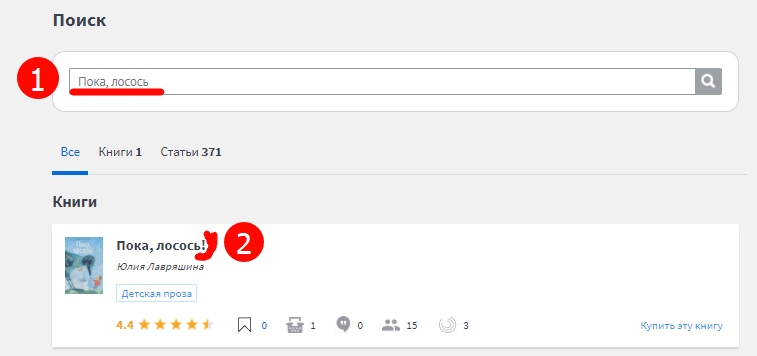
1. Спецсимвол есть в искомом поле. Вот буквально на днях студентка завела такой интересный баг на одном из сайтов поиска книг — если в запросе есть восклицательный знак, поиск не срабатывает:

При том, что сама книга на сайте есть:
И система умеет работать со спецсимволами. Скажем, по вопросительному знаку она ищет:

Поэтому проверить нужно все спецсимволы. Я обычно делаю это примерно так: создаю товар / искомый объект сразу с набором спецсимволов:
~!@#$%^&*()_+{}|:”>?<Ё!”№;%:?*()_+/Ъ,/.,;’[]\|
И по нему ищу. А вот если не срабатывает, тогда уже разбираюсь, с каким именно символом проблема.
2. Пользователь может забыть переключить раскладку и вот уже вместо «Хлеб» он вводит «{kt,»
3. Пользователь может случайно вкопипастить в поле какой-то текст со спецсимволами. Ошибки тоже надо предусмотреть, и уж точно не падать на этом =)
.
13. Эмоджи
Я специально вынесла их в отдельный пункт, чтобы вы не забыли проверить. Потому что эмоджи — это даже не совсем спецсимвол. Система может не искать по спецсимволам, но при этом падать на эмоджи. Получается, классы эквивалентности разные!
Так что в любую текстовую строку, в том числе строку поиска, обязательно вводим какую-нибудь эмоджи. Например, отсюда:
👽.
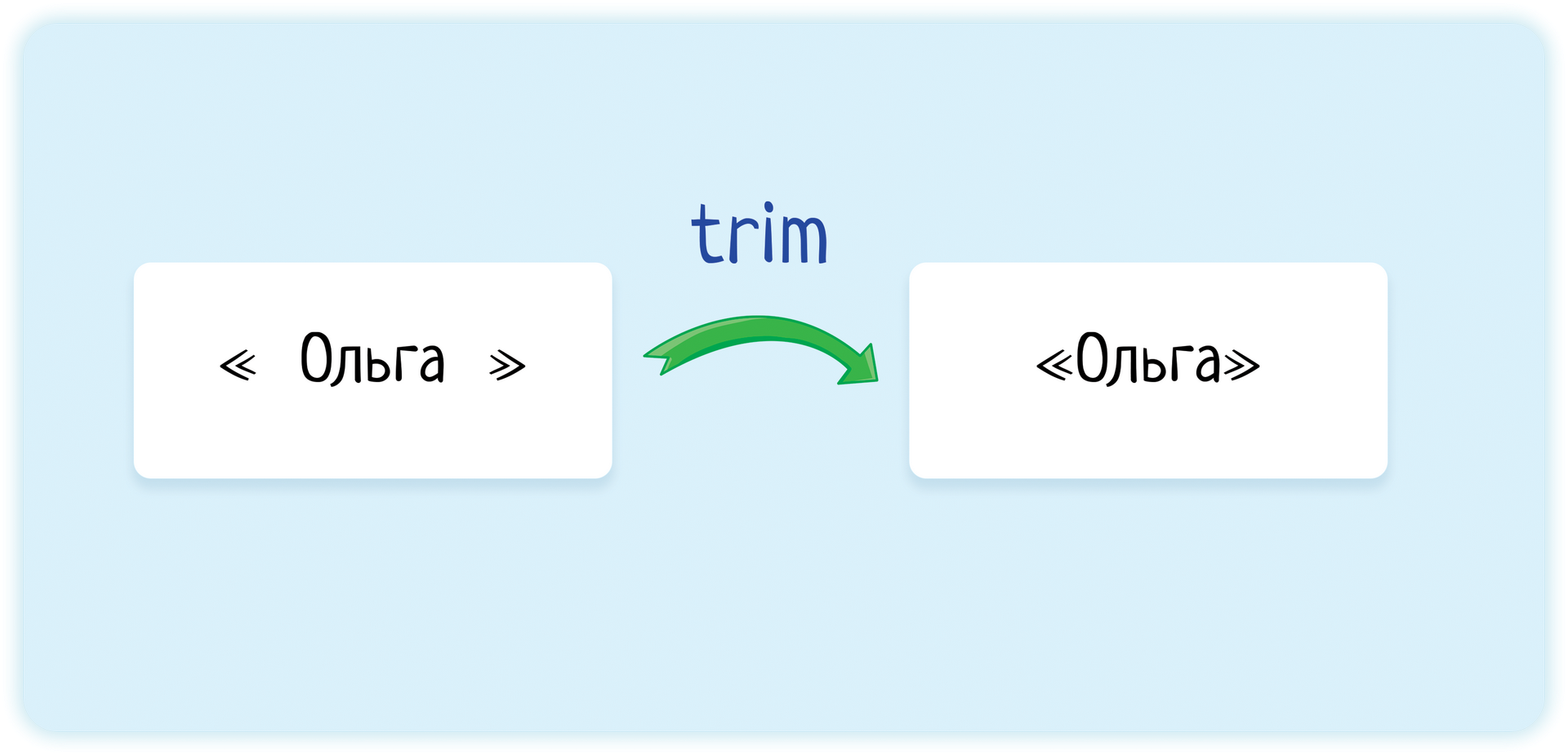
14. Тримаются ли открывающие и закрывающие пробелы
Метод trim() удаляет пробельные символы с начала и конца строки.
То есть вводим « тест », а система преобразует строку в «тест» и потом уже передаёт дальше, в нашем случае — функции поиска.
Надо признать, что проверка на трим более логична при заполнении и сохранении полей — ввела случайно « Ольга» в имя, а потом поиск не находит, требуя точного совпадения. И тогда логично системе перед сохранением сделать трим.
В поиске обычно пробелы используются как разделители слов. Поэтому пробелом больше, пробелом меньше — системе неважно.
Хотя лидирующий пробел всегда интересно проверить — а что, если система посчитает « майка» за пустую строку, так как обнаружила в первом поле пробел и посчитала строку мусорной?
.
15. Пустое поле
Фактически это проверка на ноль. А ноль — это отдельный класс эквивалентности, который часто приносит баги, поэтому его надо проверять!
См также:
Класс эквивалентности «Ноль-не ноль» — подробнее о нуле

Если мы оставили поисковую строку пустой, то есть варианты:
Система выводит всю базу
Система выводит пустоту
Кнопка поиска просто не срабатывает / вообще заблокирована до ввода символов (что сомнительно, впрочем, да и зачем?)
.
16. Пробелы в поле
Ещё один вариант тестирования нуля — ввести в поле ТОЛЬКО пробелы. Как система их обработает?
По идее также, как и пустую строку. Но может быть так, что при пустой строке выводится вообще всё, а вот если ты начал что-то вводить — начинается поиск. И хотя пробел наверняка встречается в искомых полях, найдет ли система хоть что-то?
Впрочем, в данном тесте мы просто собираем информацию о том, как работает система. Потому что почти любое поведение (разве что кроме ошибки) можно считать нормальным.
.
17. Нижняя граница
Пустое поле (ноль) — мы уже проверили. А дальше думаем, какая у наших данных будет нижняя граница?
Важно подобрать её осознанно, а не просто ввести одну букву и потом заводить баг, что вы ожидали что-то другое (и обязательно при этом добавить «если не исправите, пользователи обидятся и уйдут!»)
Павел Абдюшев в своем докладе «Есть фича. Помогите протестировать!» привел замечательный пример с писателем и поэтом Эдгаром ПО. Это пример короткой реальной фамилии, по которой могут искать.
А теперь пойдем на OZON, который раньше, на минуточку, только книги и продавал, и попробуем найти там книгу «Ворон».
Сначала пробуем по фамилии:
ПО

Хммм, нет, даже среди вариантов не предлагает, думаем, что мы ввели начало слова. Ладно, попробуем с названием книги:
ПО ворон
Теперь Озон нашел нужную книгу, вот только я могу её не заметить, так как над ней аж 7 рекламных пункта:

Пожалуй, нажму «энтер», чтобы перейти на страницу результатов поиска. Нашлась!

Так что Озон с задачей справился. Но это Озон, а как поведет себя другой магазин с книгами, мы не знаем, пока не проверим.
Если книги автора найти не получается — то проблемы с приоритетами в выборке. Поиск по ФИО автора должен быть более релевантным, чем совпадение какого-то слова в описании.
.
18. Верхняя произвольная граница
Есть ли ограничение в строке поиска? Если есть, то оно обычно в разумных пределах — 100 / 500 / 1000 символов. И если пользователь вводит больше, то значение обрезается до максимального.
И это разумно. Всегда лучше не дать ошибиться (не дать ввести больше N, обрезать запрос самостоятельно), чем ругаться на пользователя «да ты дурак, куда так много вводишь!».

Начинающие тестировщики, прочитав в ТЗ про границу в 1000 символов, записывают в свои чек-листы ожидаемый результат «при вводе больше система выдает ошибку». Но зачем выводить ошибку там, где можно обойтись без неё? Если системы ещё нет и вы пишете чек-лист заранее, просто уточните, как она будет работать.
Иногда верхнюю границу просто не ставят. И это тоже нормально, это не баг, который надо срочно исправить. Просто верхней произвольной границы у нас не будет.
.
19. Верхняя граница на выходе
Прошлый пункт — о том, как подать много на вход. А что будет, если «много» не на входе, а на выходе? Или «где-то посередине», то есть там, где поиск идёт?
Вернулось много данных по поиску (распространенный запрос)
Много данных находится в самой системе / базе данных
Сколько времени займет поиск? И пройдет ли он вообще? А то может на поиск установлен тайм-аут в 1 минуту. И при плохом интернете / большом объеме данных он будет просто висеть-тупить, а потом отваливаться.

20. Поиск технологической границы
Для поиска технологической границы мы вбиваем в строку поиска ОЧЕНЬ БОЛЬШОЕ значение. Тут хочется напомнить, что мы живем в 21 веке, поэтому 1000 символов — не поиск технологической границы. И даже 10 000, или 100 000.
Введите 100 миллионов символов или главу «Войны и мира». Есть куча инструментов, которые помогут вам в этом.
См также:
Зачем такой тест нужен? Казалось бы, ну даже если выдаст тебе система не слишком красивую ошибку, ну сам ведь балбес, хлам ввел. Однако иногда такой тест приводит к зависанию сервера. А вот это уже серьезно.
Мы столкнулись с этим на тестовом стенде подсказок Дадаты — ввели в подсказки по организациям большой текст и подвесили систему.

Поиск там работал по условию OR → то есть механизм брал каждое слово и искал его в справочнике так:
Слушай, у тебя есть слово 1 ИЛИ слово 2 ИЛИ слово 3 ИЛИ слово 4...?
Если слов много → то и комбинаций получается много → вот он и зависал, все их перебирая… При этом зависал сервер, то есть подсказок бы никто не увидел, если бы баг дошел до продакшена. А это уже нехорошо =)
Поэтому мой вам совет при тестировании поиска — когда исследуете технологические границы, генерируйте ТЕКСТ, а не строку. То есть кучу слов с пробелами. А то вдруг ваша система тоже не выдержит много комбинаций?
Это можно сделать и через perlclip. Просто задайте условие вида
"x xxx xx " x 9999999999
.
21. А дальше что?
Это чек-лист конкретного функционала — поиска. Но стоит ли останавливаться на проверке того, что «товар найден / не найден»?
Послушайте доклад Павла Абдюшева «Есть фича. Помогите протестировать!». Он там показывает, как выйти за рамки тестирования функционала. Как посмотреть на него с разных сторон. Что ещё стоит проверить и включить в план тестирования.
Как подключить связанный функционал — например, на что обратить внимание в результатах поиска, есть ли там сразу кнопка “купить”.
.
Итого
Помните, что мы всегда начинаем тестировать с самого важного. Поиск нужен для чего? Чтобы искать по каким-то полям. Поэтому в первую очередь проверяем:
что поиск ищет по всем полям, указанным в ТЗ
что он НЕ ищет по тем полям, которые НЕ указаны в ТЗ
А потом уже начинаем проверять регистр, включение, опечатки и прочая. И идём от простого к сложному, потому что если в одном тесте проверять сразу всё, то потом очень сложно будет понять, из-за чего конкретно поиск не сработал.

Также не забывайте про стандартные тесты для любого текстового поля:
Разный регистр / язык / спецсимволы / эмоджи
Пустое поле / поле из пробелов
Нижняя граница — есть ли у вас адекватные, но короткие данные, ищет система по ним?
Верхняя произвольная граница — если она есть
Поиск технологической границы — вводим МНОГО слов, желательно с пробелами.
Но помните, что это серебряная пуля для любой текстовой строки. А, значит, она явно менее приоритетна тестов именно на ваш функционал — в данном случае на поиск. А тестировать надо начинать с самого главного!
Вы когда-нибудь пользовались поисковой системой сайта "smotrim.ru"? Судя по обилию ваших статей с отсылкой к поисковой системе вы на ней "собаку съели". Так поясните, пожалуйста, что в функционале сайта "smotrim.ru" является фичей, а что багом.
ОтветитьУдалить1. В верхней части страницы имеется кнопка для открытия формы поиска. А после получения первого результата в центре страницы появляется ещё одно поле поиска.
Такое дублирование чем обосновано? Это новый тренд?
2. По нажатию кнопки с лупой в верхней части главного окна появляется поле для ввода строки поиска.
2.1. Если по окончании ввода нажать клавишу Enter, то результат поиска окажется нулевой.
Как объяснить такое поведение? Необработанное стандартное действие пользователя или что-то новенькое в программировании?
2.2. После 2-3 секундной задержки при вводе поисковой строки появляется ниспадающий список с совпадениями, клик по которым открывает искомый ролик. Ещё месяц-другой назад этот же список найденного, но в виде ячеек с картинками и подписями, отрисовывался по нажатию клавиши Enter. Это убеждает меня, что предшествующий пункт - явный баг.
Но поскольку ниспадающий список отрабатывает в ожидаемом режиме, то гипотетически такое поведение - современный тренд поисковой системы. А как вы считаете?
3. По-моему, в вашем чит-листе не хватает пункта про отображение результатов поиска:
- умещается ли всё важное на первой странице;
- в каком виде отображается результат (список, таблица, ...);
- имеются ли последующие линки или графические элементы для увеличения инфы о найденном объекте;
- достаточно ли инфы про каждый найденный элемент;
- можно ли запустить вложенный поиск среди результатов первого уровня (когда-то первый русскоязычный поисковик имел галку "найти в найденном").
Нет, не пользовалась
Удалить1. Не в курсе трендов, но меня устраивают поисковые строки вайлдберриз, озон и иже с ними)
2. Это могут делать для экономии места, но для пользователя лищнее действие
2.1. Не знаю как пояснить, но судя по пункту 2.2 вы обязаны сделать выбор из выпадающего списка. И раз вы просто жмете "энтер", ничего не выбрав, то поле остается пустым. Так на всяких гос сайтах делают ввод адреса, только выбор из их вариантов и никак иначе
2.2. Так себе тренд с точки зрения юзабилити)
3. У меня есть про самое важное) Только зачем ограничиваться первой страницей?
А про "в каком виде отображается" и прочее есть в последнем пункте, в Пашином докладе, но у меня речь про функционал поиска скорее
К пункту о небуквенных символах. На сайте "smotrim.ru" поиск ролика с запятой или точкой не работает, если поисковая строка вставлена из буфера, а не набрана вручную. Своеобразный баг, да?
УдалитьДа)
УдалитьУ некоторых ваших статей есть дубликаты на Хабре только потому, что там легче формировать содержание?
ОтветитьУдалитьА вы знаете, что текущий блог-сервис не запрещает использование параметра "name" в тэге "a", что позволяет вручную конструировать содержание статьи и заголовки её частей.
Надеюсь, эта подсказка упростит вам процесс компоновки статей.
У Хабра больше охват аудитории, он лучше гуглится.
УдалитьИ да, содержание там можно сделать, в блоггере я пыталась вставить html-разметку с hfer, но они не работали
Если в месте начала главы использовать только параметр "name", а в содержании параметр "href" постфиксовать через решётку назначенным именем метки, то получатся ссылки от содержания к главам внутри статьи.
УдалитьСмотрите примеры в "tjupka.blogspot.com/2018/06/easy-white-box-testing.html" и "https://tjupka.blogspot.com/2021/05/blog-post.html".
Попробую в следующий раз как-нибудь, спасибо)
Удалить