Система контроля версий (от англ. Version Control System, VCS) — это место хранения кода. Как dropbox, только для разработчиков!

Она заточена именно на разработку продуктов. То есть на хранение кода, синхронизацию работы нескольких человек, создание релизов (бранчей)... Но давайте я лучше расскажу на примере, чем она лучше дропбокса. Всё как всегда, история с кучей картиночек для наглядности ))
А потом я подробнее расскажу, как VCS работает — что значит "создать репозиторий", "закоммитить и смерджить изменения", и другие страшные слова. В конце мы пощупаем одну из систем VCS руками, скачаем код из открытого репозитория.
Что это такое и зачем она нужна
Допустим, что мы делаем калькулятор на Java (язык программирования). У нас есть несколько разработчиков — Вася, Петя и Иван. Через неделю нужно показывать результат заказчику, так что распределяем работу:
Вася делает сложение;
Петя — вычитание;
Иван — начинает умножение, но оно сложное, поэтому переедет в следующий релиз.
Исходный код калькулятора хранится в обычной папке на сетевом диске, к которому все трое имеют доступ. Разработчик копирует этот код к себе на машину, вносит изменения и проверяет. Если всё хорошо — кладет обратно. Так что код в общей папке всегда рабочий!
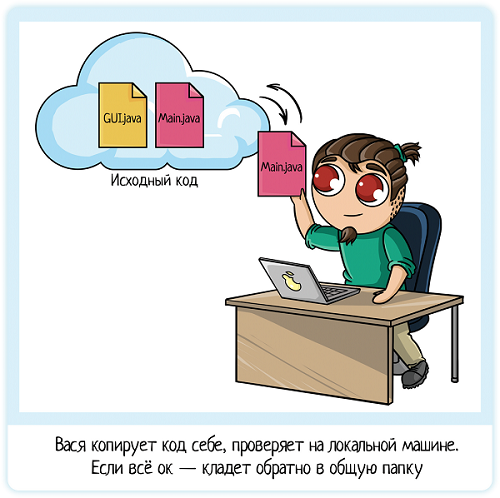
Итак, все забрали себе файлы из общей папки. Пока их немного:
Main.java — общая логика
GUI.java — графический интерфейс программы
С ними каждый и будет работать!
Вася закончил работу первым, проверил на своей машине — все работает, отлично! Удовлетворенно вздохнув, он выкладывает свой код в общую папку. Вася сделал отдельный класс на сложение (Sum.java), добавил кнопку в графический интерфейс (внес изменения в GUI.java) и прописал работу кнопки в Main.java.

Петя химичил-химичил, ускорял работу, оптимизировал... Но вот и он удовлетворенно вздохнул — готово! Перепроверил ещё раз — работает! Он копирует файлы со своей машины в общую директорию. Он тоже сделал отдельный класс для новой функции (вычитание — Minus.java), внес изменения в Main.java и добавил кнопку в GUI.java.

Ваня пока химичит на своей машине, но ему некуда торопиться, его изменения попадут только в следующий цикл.
Все довольны, Вася с Петей обсуждают планы на следующий релиз. Но тут с показа продукта возвращается расстроенная Катя, менеджер продукта.
— Катя, что случилось??
— Вы же сказали, что всё сделали! А в графическом интерфейсе есть только вычитание. Сложения нет!
Вася удивился:
— Как это нет? Я же добавлял!
Стали разбираться. Оказалось, что Петин файл затер изменения Васи в файлах, которые меняли оба: Main.java и GUI.java. Ведь ребята одновременно взяли исходные файлы к себе на компьютеры — у обоих была версия БЕЗ новых функций.

Вася первым закончил работу и обновил все нужные файлы в общей папке. Да, на тот момент всё работало. Но ведь Петя работал в файле, в котором ещё не было Васиных правок.

Поэтому, когда он положил документы в хранилище, Васины правки были стерты. Остался только новый файл Sum.java, ведь его Петя не трогал.

Хорошо хоть логика распределена! Если бы всё лежало в одном классе, было бы намного сложнее совместить правки Васи и Пети. А так достаточно было немного подправить файлы Main.java и GUI.java, вернув туда обработку кнопки. Ребята быстро справились с этим, а потом убедились, что в общем папке теперь лежит правильная версия кода.
Собрали митинг (жаргон — собрание, чтобы обсудить что-то):
— Как нам не допустить таких косяков в дальнейшем?
— Давайте перед тем, как сохранять файлы в хранилище, забирать оттуда последние версии! А ещё можно брать свежую версию с утра. Например, в 9 часов. А перед сохранением проверять дату изменения. Если она позже 9 утра, значит, нужно забрать измененный файл.
— Да, давайте попробуем!

Вася с Петей были довольны, ведь решение проблемы найдено! И только Иван грустит. Ведь он целую неделю работал с кодом, а теперь ему надо было синхронизировать версии... То есть объединять свои правки с изменениями коллег.

Доделав задачу по умножению, Иван синхронизировал свои файлы с файлами из хранилища. Это заняло половину рабочего дня, но зато он наконец-то закончил работу! Довольный, Иван выключил компьютер и ушел домой.
Когда он пришел с утра, в офисе был переполох. Вася бегал по офису и причитал:
— Мои изменения пропали!!! А я их не сохранил!
Увидев Ваню, он подскочил к нему и затряс за грудки:
— Зачем ты стер мой код??

Стали разбираться. Оказалось что Вася вчера закончил свой кусок работы, проверил, что обновлений файлов не было, и просто переместил файлы со своего компьютера в общую папку. Не скопировал, а переместил. Копий никаких не осталось.
После этого изменения вносил Иван. Да, он внимательно вычитывал файлы с кодом и старался учесть и свои правки, и чужие. Но изменений слишком много, часть Васиных правок он потерял.
— Код теперь не работает! Ты вообще проверял приложение, закончив синхронизацию?
— Нет, я только свою часть посмотрел...

Вася покачал головой:
— Но ведь при сохранении на общий диск можно допустить ошибку! По самым разным причинам:
Разработчик начинающий, чаще допускает ошибки.
Случайно что-то пропустил — если нужно «объединить» много файлов, что-то обязательно пропустишь.
Посчитал, что этот код не нужен — что он устарел или что твоя новая логика делает то же самое, а на самом деле не совсем.
И тогда приложение вообще перестанет работать. Как у нас сейчас.
Ваня задумался:
— Хм... Да, пожалуй, ты прав. Нужно тестировать итоговый вариант!
Петя добавил:
— И сохранять версии. Может, перенесем наш код в Dropbox, чтобы не терять изменения?

На том и порешили. Остаток дня все трое работали над тем, чтобы приложение снова заработало. После чего бережно перенесли код в дропбокс. Теперь по крайней мере сохранялись старые версии. И, если разработчик криво синхронизировал файлы или просто залил свои, затерев чужие изменения, можно было найти старую версию и восстановить ее.
Через пару дней ребята снова собрали митинг:
— Ну как вам в дропбоксе?
— Уже лучше. По крайней мере, не потеряем правки!
Петя расстроенно пожимает плечами:
— Да, только мы с Васей одновременно вносили изменения в Main.java, создалась конфликтующая версия. И пришлось вручную их объединять... А класс то уже подрос! И глазками сравнивать 100 строк очень невесело... Всегда есть шанс допустить ошибку.
— Ну, можно же подойти к тому, кто создал конфликт и уточнить у него, что он менял.
— Хорошая идея, давайте попробуем!

Попробовали. Через несколько дней снова митинг:
— Как дела?
— Да всё зашибись, работаем!
— А почему код из дропбокса не работает?
— Как не работает??? Мы вчера с Васей синхронизировались!
— А ты попробуй его запустить.
Посмотрели все вместе — и правда не работает. Какая-то ошибка в Main.java. Стали разбираться:
— Так, тут не хватает обработки исключения.
— Ой, подождите, я же её добавлял!
— Но ты мне не говорил о ней, когда мы объединяли правки.
— Да? Наверное, забыл...
— Может, еще что забыл? Ну уж давай лучше проверим глазами...

Посидели, выверили конфликтные версии. Потратили час времени всей команды из-за пустяка. Обидно!
— Слушайте, может, это можно как-то попроще делать, а? Чтобы человека не спрашивать «что ты менял»?
— Можно использовать программу сравнения файлов. Я вроде слышал о таких. AraxisMerge, например!
— Ой, точно! В IDEA же можно сравнивать твой код с клипбордом (сохраненным в Ctrl + C значении). Давайте использовать его!
— Точно!
Начали сравнивать файлы через программу — жизнь пошла веселее. Но через пару дней Иван снова собрал митинг:
— Ребята, тут такая тема! Оказывается, есть специальные программы для хранения кода! Они хранят все версии и показывают разницу между ними. Только делает это сама программа, а не человек!
— Да? И что за программы?
— Системы контроля версий называются. Вот SVN, например. Давайте попробуем его?
— А давайте!

Попробовали. Работает! Еще и часть правок сама синхронизирует, даже если Вася с Петей снова не поделили один файл. Как она это делает? Давайте разбираться!
Как VCS работает
Подготовительная работа
Это те действия, которые нужно сделать один раз.
1. Создать репозиторий
Исходно нужно создать место, где будет лежать код. Оно называется репозиторий. Создается один раз администратором.
Ребята готовы переехать из дропбокса в SVN. Сначала они проверяют, что в дропбоксе хранится актуальная версия кода, ни у кого не осталось несохраненных исправлений на своей машине. Потом ребята проверяют, что «итоговый» код работает.
А потом Вася берет код из дропбокса, и кладет его в VCS специальной командой. В разных системах контроля версии разные названия у команды, но суть одна — создать репозиторий, в котором будет храниться код.
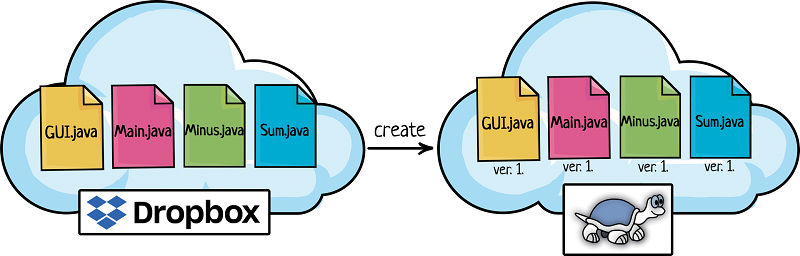
Всё! Теперь у нас есть общее хранилище данных! С ним дальше и будем работать.
2. Скачать проект из репозитория
Теперь команде нужно получить проект из репозитория. Можно, конечно, и из дропбокса скачать, пока там актуальная версия, но давайте уже жить по-правильному!
Поэтому Петя, Вася и Иван удаляют то, что было у них было на локальных компьютерах. И забирают данные из репозитория, клонируя его. В Mercurial (один из вариантов VCS) эта команда так и называется — clone. В других системах она зовется иначе, но смысл всё тот же — клонировать (копировать) то, что лежит в репозитории, к себе на компьютер!

Забрать код таким образом нужно ровно один раз, если у тебя его ещё не было. Дальше будут использоваться другие команды для передачи данных туда-сюда.
А когда на работу придет новый сотрудник, он сделает то же самое — скачает из репозитория актуальную версию кода.

Ежедневная работа
А это те действия, которые вы будете использовать часто.
1. Обновить проект, забрать последнюю версию из репозитория
Приходя утром на работу, нужно обновить проект на своем компьютере. Вдруг после твоего ухода кто-то вносил изменения?
Так, Вася обновил проект утром и увидел, что Ваня изменил файлы Main.java и GUI.java. Отлично, теперь у Васи актуальная версия на машине. Можно приступать к работе!

В SVN команда обновления называется «update», в Mercurial — «pull». Она сверяет код на твоем компьютере с кодом в репозитории. Если в репозитории появились новые файлы, она их скачает. Если какие-то файлы были удалены — удалит и с твоей машины тоже. А если что-то менялось, обновит код на локальном компьютере.

Тут может возникнуть вопрос — в чем отличие от clone? Можно же просто клонировать проект каждый раз, да и всё! Зачем отдельная команда?
Клонирование репозитория производится с нуля. А когда разработчики работают с кодом, у них обычно есть какие-то локальные изменения. Когда начал работу, но ещё не закончил. Но при этом хочешь обновить проект, чтобы конфликтов было меньше.
Если бы использовалось клонирование, то пришлось бы переносить все свои изменения в «новый» репозиторий вручную. А это совсем не то, что нам нужно. Обновление не затронет новые файлы, которые есть только у вас на компьютере.
А еще обновление — это быстрее. Обновиться могли 5 файликов из 1000, зачем выкачивать всё?
2. Внести изменения в репозиторий
Вася работает над улучшением сложения. Он придумал, как ускорить его работу. А заодно, раз уж взялся за рефакторинг (жаргон — улучшение системы, от англ. refactor), обновил и основной класс Main.java.
Перед началом работы он обновил проект на локальном (своём) компьютере, забрав из репозитория актуальные версии. А теперь готов сохранить в репозиторий свои изменения. Это делается одной или двумя командами — зависит от той VCS, которую вы используете в работе.
1 команда — commit
Пример системы — SVN.
Сделав изменения, Вася коммитит их. Вводит команду «commit» — и все изменения улетают на сервер. Всё просто и удобно.

2 команды — commit + push
Примеры системы — Mercurial, Git.
Сделав изменения, Вася коммитит их. Вводит команду «commit» — изменения сохранены как коммит. Но на сервер они НЕ уходят!

Чтобы изменения пошли на сервер, их надо «запушить». То есть ввести команду «push».
Это удобно, потому что можно сделать несколько разных коммитов, но не отправлять их в репозиторий. Например, потому что уже code freeze и тестировщики занимаются регрессией. Или если задача большая и может много всего сломать. Поэтому её надо сначала довести до ума, а потом уже пушить в общий репозиторий, иначе у всей команды развалится сборка!
При этом держать изменения локально тоже не слишком удобно. Поэтому можно спокойно делать коммиты, а потом уже пушить, когда готов. Или когда интернет появился =) Для коммитов он не нужен.
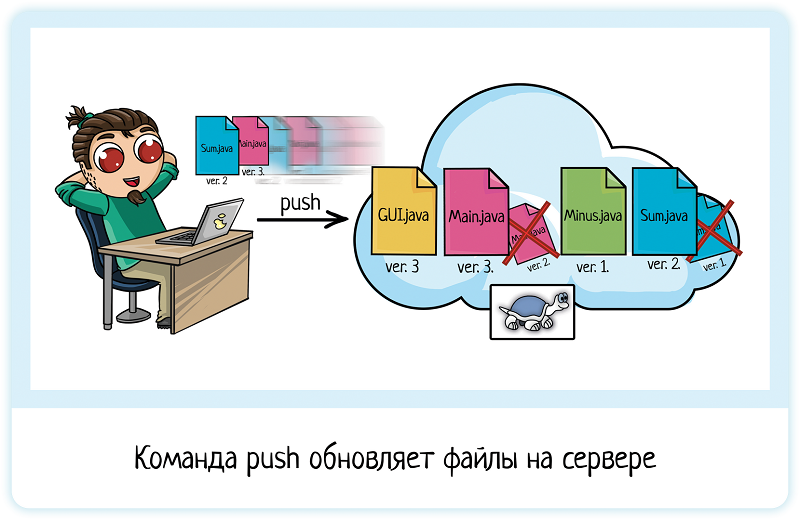
Итого
Когда разработчик сохраняет код в общем хранилище, он говорит:
— Закоммитил.
Или:
— Запушил.
Смотря в какой системе он работает. После этих слов вы уверены — код изменен, можно обновить его на своей машине и тестировать!
3. Разрешить конфликты (merge)
Вася добавил вычисление процентов, а Петя — деление. Перед работой они обновили свои локальные сборки, получив с сервера версию 3 файлов Main.java и Gui.java.
Для простоты восприятия нарисуем в репозитории только эти файлы и Minus.java, чтобы показать тот код, который ребята трогать не будут.

Вася закончил первым. Проверив свой код, он отправил изменения на сервер. Он:
Добавил новый файл Percent.java
Обновил Main.java (версию 3)
Обновил Gui.java (версию 3)
При отправке на сервер были созданы версии:
Percent.java — версия 1
Main.java — версия 4
Gui.java — версия 4

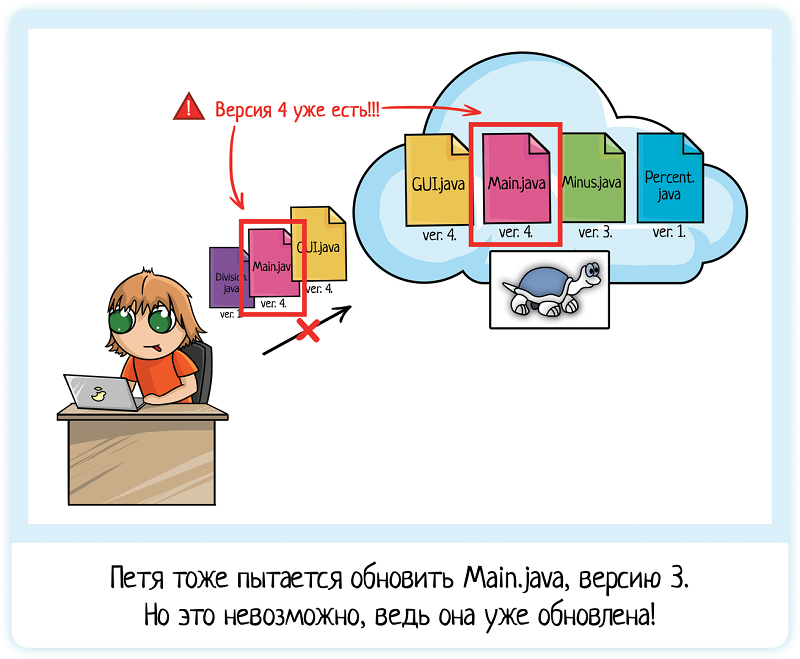
Петя закончил чуть позже. Он:
Добавил новый файл Division.java
Обновил Main.java (версию 3, ведь они с Васей скачивали файлы одновременно)
Обновил Gui.java (версию 3)
Готово, можно коммитить! При отправке на сервер были созданы версии:
Division.java — версия 1
Main.java — версия 4
Gui.java — версия 4
Но стойте, Петя обновляет файлы, которые были изменены с момента обновления кода на локальной машине! Конфликт!
Часть конфликтов система может решить сама, ей достаточно лишь сказать «merge». И в данном случае этого будет достаточно, ведь ребята писали совершенно разный код, а в Main.java и Gui.java добавляли новые строчки, не трогая старые. Они никак не пересекаются по своим правкам. Поэтому система «сливает» изменения — добавляет в версию 4 Петины строчки.
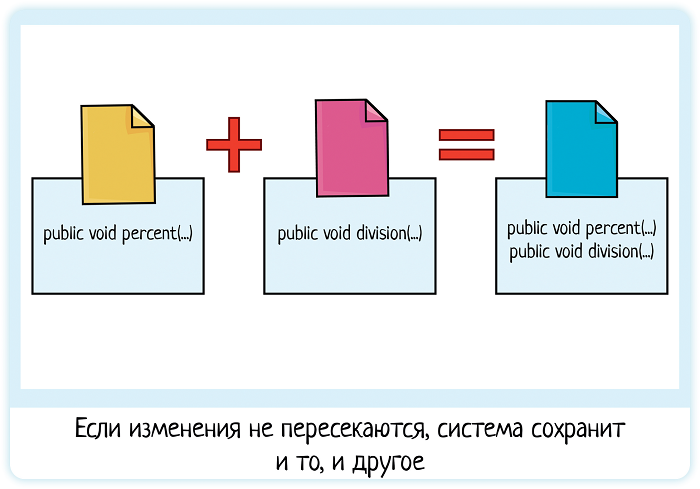
Но что делать, если они изменяли один и тот же код? Такой конфликт может решить только человек. Система контроля версий подсвечивает Пете Васины правки и он должен принять решение, что делать дальше. Система предлагает несколько вариантов:
Оставить Васин код, затерев Петины правки — если Петя посмотрит Васны изменения и поймет, что те лучше
Затереть Васины правки, взяв версию Петра — если он посчитает, что сам все учел
Самому разобраться — в таком случае в файл кода добавляются обе версии и надо вручную слепить из них итоговый кусок кода
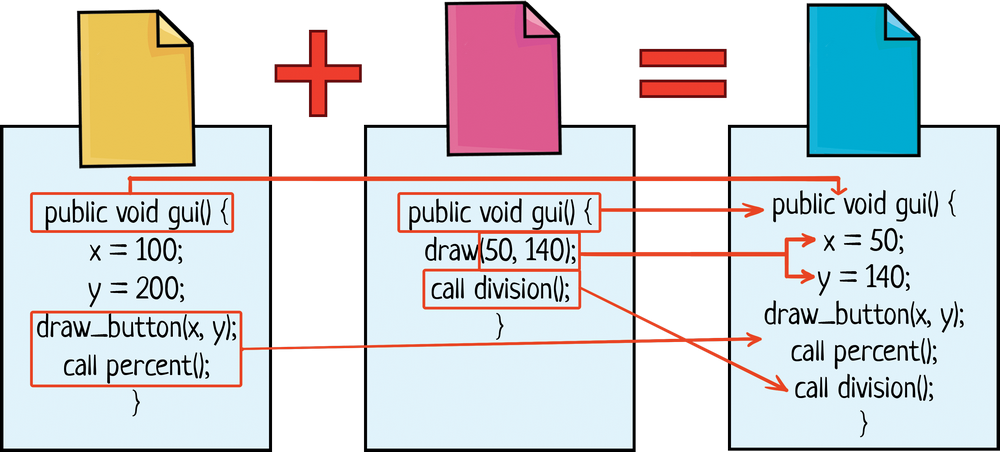
Разрешение конфликтов — самая сложная часть управления кодом. Разработчики стараются не допускать их, обновляя код перед тем, как трогать файл. Также помогают небольшие коммиты после каждого завершенного действия — так другие разработчики могут обновиться и получить эти изменения.
Но, разумеется, конфликты все равно бывают. Разработчики делают сложные задачи, на которые уходит день-два. Они затрагивают одни и те же файлы. В итоге, вливая свои изменения в репозиторий, они получают кучу конфликтов, и нужно просмотреть каждый — правильно ли система объединила файлы? Не нужно ли ручное вмешательство?
Особая боль — глобальный рефакторинг, когда затрагивается МНОГО файлов. Обновление версии библиотеки, переезд с ant на gradle, или просто выкашивание легаси кода. Нельзя коммитить его по кусочкам, иначе у всей команды развалится сборка.
Поэтому разработчик сначала несколько дней занимается своей задачей, а потом у него 200 локальных изменений, среди которых явно будут конфликты.

А что делать? Обновляет проект и решает конфликты. Иногда в работе над большой задачей разработчик каждый день обновляется и мерджит изменения, а иногда только через несколько дней.
Тестировщик будет сильно реже попадать в конфликтные ситуации, просто потому, что пишет меньше кода. Иногда вообще не пишет, иногда пополняет автотесты. Но с разработкой при этом почти не пересекается. Однако выучить merge все равно придется, пригодится!
4. Создать бранч (ветку)
На следующей неделе нужно показывать проект заказчику. Сейчас он отлично работает, но разработчики уже работают над новыми изменениями. Как быть? Ребята собираются на митинг:
— Что делать будем? Не коммитить до показа?
— У меня уже готовы новые изменения. Давайте закоммичу, я точно ничего не сломал.
Катя хватается за голову:
— Ой, давайте без этого, а? Мне потом опять краснеть перед заказчиками!
Тут вмешивается Иван:
— А давайте бранчеваться!

Все оглянулись на него:
— Что делать?
Иван стал рисовать на доске:
— Бранч — это отдельная ветка в коде. Вот смотрите, мы сейчас работаем в trunk-е, основной ветке.

Когда мы только-только добавили наш код на сервер, у нас появилась «точка возврата» — сохраненная версия кода, к которой мы можем обратиться в любой момент.

Потом Вася закоммитил изменения по улучшению классов — появилась версия 1 кода.

Потом он добавил проценты — появилась версия кода 2.

При этом в самой VCS сохранены все версии, и мы всегда можем:
Посмотреть изменения в версии 1
Сравнить файлы из версии 1 и версии 2 — система наглядно покажет, где они совпадают, а где отличаются
Откатиться на прошлую версию, если версия 2 была ошибкой.

Потом Петя добавил деление — появилась версия 3.

И так далее — сколько сделаем коммитов, столько версий кода в репозитории и будет лежать. А если мы хотим сделать бранч, то система копирует актуальный код и кладет отдельно. На нашем стволе появляется новая ветка (branch по англ. — ветка). А основной ствол обычно зовут trunk-ом.

Теперь, если я захочу закоммитить изменения, они по-прежнему пойдут в основную ветку. Бранч при этом трогать НЕ будут (изменения идут в ту ветку, в которой я сейчас нахожусь. В этом примере мы создали branch, но работать продолжаем с trunk, основной веткой)
Так что мы можем смело коммитить новый код в trunk. А для показа использовать branch, который будет оставаться стабильным даже тогда, когда в основной ветке всё падает из-за кучи ошибок.
С бранчами мы всегда будем иметь работающий код!

— Подожди, подожди! А зачем эти сложности? Мы ведь всегда может просто откатиться на нужную версию! Например, на версию 2. И никаких бранчей делать не надо!
— Это верно. Но тогда тебе нужно будет всегда помнить, в какой точке у тебя «всё работает и тут есть все нужные функции». А если делать говорящие названия бранчей, обратиться к ним намного проще. К тому же иногда надо вносить изменения именно в тот код, который на продакшене (то есть у заказчика).
Вот смотри, допустим, мы выпустили сборку 3, идеально работающую. Спустя неделю Заказчик ее установил, а спустя месяц нашел баг. У нас за эти недели уже 30 новых коммитов есть и куча изменений.
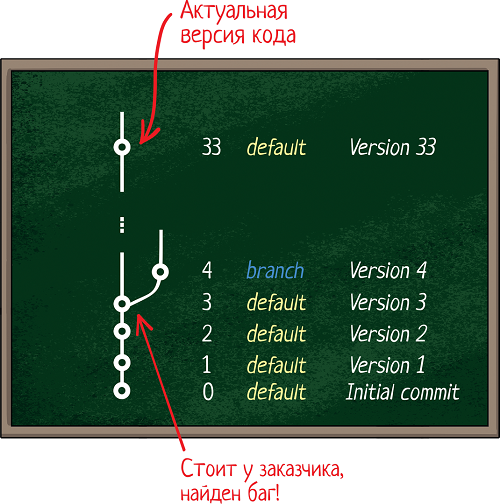
Заказчику нужно исправление ошибки, но он не готов ставить новую версию — ведь ее надо тестировать, а цикл тестирования занимает неделю. А баг то нужно исправить здесь и сейчас! Получается, нам надо:
Обновиться на версию 3
Исправить баг локально (на своей машине, а не в репозитории)
Никуда это не коммитить = потерять эти исправления
Собрать сборку локально и отдать заказчику
Не забыть скопипастить эти исправления в актуальную версию кода 33 и закоммитить (сохранить)
Что-то не очень весело. А если нужно будет снова дорабатывать код? Искать разработчика, у которого на компьютере сохранены изменения? Или скопировать их и выложить на дропбокс? А зачем тогда использовать систему контроля версий?

Именно для этого мы и бранчуемся! Чтобы всегда иметь возможность не просто вернуться к какому-то коду, но и вносить в него изменения. Вот смотрите, когда Заказчик нашел баг, мы исправили его в бранче, а потом смерджили в транк.
Смерджили — так называют слияние веток. Это когда мы внесли изменения в branch и хотим продублировать их в основной ветке кода (trunk). Мы ведь объединяем разные версии кода, там наверняка есть конфликты, а разрешение конфликтов это merge, отсюда и название!

Если Заказчик захочет добавить новую кнопочку или как-то еще изменить свою версию кода — без проблем. Снова вносим изменения в нужный бранч + в основную ветку.
Веток может быть много. И обычно чем старше продукт, тем больше веток — релиз 1, релиз 2... релиз 52...
Есть программы, которые позволяют взглянуть на дерево изменений, отрисовывая все ветки, номера коммитов и их описание. Именно в таком стиле, как показано выше =) В реальности дерево будет выглядеть примерно вот так (картинка из интернета):

А иногда и ещё сложнее!
— А как посмотреть, в какой ветке ты находишься?
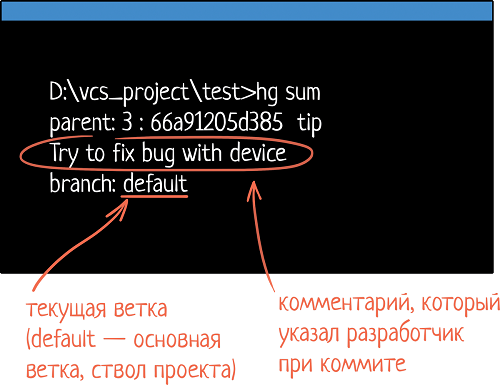
— О, для этого есть специальная команда. Например, в Mercurial это «hg sum»: она показывает информацию о том, где ты находишься. Вот пример ее вызова:
В данном примере «parent» — это номер коммита. Мы ведь можем вернуться на любой коммит в коде. Вдруг мы сейчас не на последнем, не на актуальном? Можно проверить. Тут мы находимся на версии 3. После двоеточия идет уникальный номер ревизии, ID кода.

Потом мы видим сообщение, с которым был сделан коммит. В данном случае разработчик написал «Try to fix bug with device».
И, наконец, параметр «branch»! Если там значение default — мы находимся в основной ветке. То есть мы сейчас в trunk-е. Если бы были не в нём, тут было бы название бранча. При создании бранча разработчик даёт ему имя. Оно и отображается в этом пункте.
— Круто! Давайте тогда делать ветку!
*****
Для Git создали интерактивную «игрушку», чтобы посмотреть на то, как происходит ветвление — https://learngitbranching.js.org
Создал её Peter Cottle
*****
Отдельно хочу заметить, что бранчевание на релиз — не единственный вариант работы с VCS. Есть и другой подход к разработке — когда транк поддерживают в актуальном и готовом к поставкам состоянии, а все задачи делают в отдельных ветках. Но его мы в этой статье рассматривать не будем.
Итого
Система контроля версий (от англ. Version Control System, VCS) — это dropbox для кода.
Популярные VCS и отличия между ними
Наиболее популярные — это:
SVN — простая, но там очень сложно мерджиться
Mercurial (он же HG), Git — намного больше возможностей (эти системы похожи по функционалу)
SVN — очень простая система, одна из первых. Сделал — закоммитил. Всё! Для небольшого проекта её вполне достаточно. Вы можете делать разные ветки и мерджить хоть туда, хоть сюда. Но у неё так себе работает автомитический мерджа, на моей практике приходилось каждый файлик брать и копипастить изменения в основную ветку, это было проще, чем смерджить.
@lizardus в комментариях на Хабре добавил о преимуществах системы:
Главные трудности в svn — всегда нужна сеть, и он может быть очень мммееееддддленный. Ну и с ветками работать не так удобно, в svn это просто директории. Хотя для новичков "папки" svn обычно интуитивнее.
А в целом, svn просто другая система (он работает просто как файловая система) со своими преимуществами и недостатками. Его легко поставить на windows (не тянет за собой треть линукса), он безопасен (все что закоммичено — сохранено навеки, удалить нельзя ничего, никакого rebase), легко сделать checkout одной маленькой части проекта и работать только с ней (а это позволяет модный монорепо без костылей), можно мешать ревизии отдельных файлов в папке проекта и мерджить отдельные файлы произвольным образом. Права доступа к отдельным частям проекта — легко. svn работает с бинарными данными и даже (теоретически) как-то мерджит. Легко аутентификацию по сертификату. Встроенный WebDAV с минимальными усилиями: можно смонтировать как диск в Windows для тех, кому нужен доступ только для чтения, или просто бросить ссылку для браузера (какие-нибудь дизайнеры так могут любоваться картинками из svn или скрипт может получать последние бинарные данные для управления коллайдером).
Mercurial и Git — распределенная система контроля версий. Внесение изменений двухступенчатое — сначала коммит, потом push. Это удобно, если вы работаете без интернета, или делаете мелкие коммиты, но не хотите ломать основной код пока не доделаете большую задачу. Тут есть и автоматическое слияние разных бранчей. Больше возможностей дают системы.
У любой системы контроля версий есть «консольный интерфейс». То есть общаться с ними можно напрямую через консоль, вводя туда команды. Склонировать репозиторий, обновить его, добавить новый файл, удалить старый, смерджить изменения, создать бранч... Всё это делается с помощью команд.
Но есть и графический интерфейс. Устанавливаете отдельную программу и выполняете действия мышкой. Обычно в моей практике это делается через «черепашку» — программа называется Tortoise<VCS>. TortoiseSVN, TortoiseHG, TortoiseGit... Часть команд можно сделать через среду разработки — IDEA, Eclipse, etc. Плюс есть еще куча других инструментов, часть из них можно найти в комментариях =)
Но любой графический интерфейс как работает? Вы потыкали мышкой, а система Tortoise составила консольную команду из вашего «тык-тык», её и применила.
См также:
Что такое API — подробнее о том, что скрывается за интерфейсом.
Вот некоторые базовые команды и форма их записи в разных VCS:
Действие | SVN | GIT | HG |
Клонировать репозиторий | svn checkout <откуда> <куда> | git clone <откуда> <куда> | hg clone <откуда> <куда> |
Обновить локальную сборку из репозитория | svn update | git pull | hg pull -u |
Проверить текущую версию (где я есть?) | svn log --revision HEAD | git show -s | hg sum |
Закоммитить изменения | svn commit -m "MESSAGE" | git commit -a -m "MESSAGE"
| hg commit -m "MESSAGE"
|
Переключиться на branch | svn checkout <откуда> <куда> | git checkout BRANCH | hg update BRANCH |
Тут хочу напомнить, что я тестировщик, а не разработчик. Поэтому про тонкости различия коммитов писать не буду, да и статья для новичков, оно им и не надо =)
Пример — выкачиваем проект из Git
Выкачивать мы будем систему с открытым исходным кодом Folks. Так что вы можете повторить этот пример сами!
Для начала установите Git. Когда он установлен, можно выкачивать репозиторий на свой компьютер. Я покажу 3 способа (есть и другие, но я покажу именно эти):
Через консоль
Через IDEA
Через TortoiseGit
Исходный код мы будем в директорию D:\git.
1. Через консоль
1. Запустить консоль git:

2. Написать команду:
↓
В консоли нужно писать простой слеш или экранировать обратный. Иначе консоль его проигнорирует!
Также НЕ НАДО использовать в названии папки «куда клонируем» русские символы или пробелы. Иначе потом огребете проблем на сборке проекта.
2. Через IDEA
1. Запустить IDEA
2. Check out from Version Control → Git

3. Заполнить поля:
URL — https://bitbucket.org/testbasecode/folks/src/master/ (откуда выкачиваем исходный код)
Назначение — D:\git\folks_idea (куда сохраняем на нашем компьютере)

4. Нажать Clone — всё! Дальше IDEA всё сделает сама!
А под конец предложит открыть проект, подтверждаем!

Если открывается пустой серый экран, найдите закладку «Project» (у меня она слева сверху) и щелкните по ней, чтобы раскрыть проект:
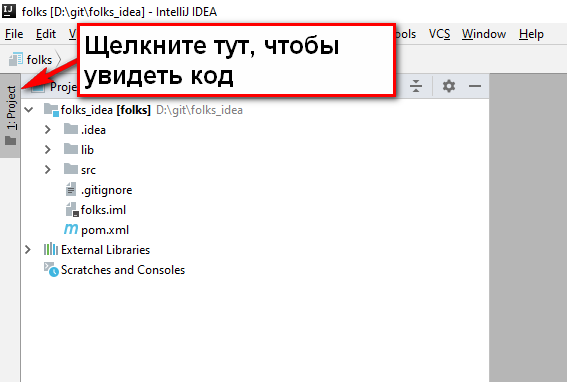
И вуаля — и код скачали, и сразу в удобном и бесплатном редакторе открыли! То, что надо. Для новичка так вообще милое дело.
3. Через TortoiseGit
Еще один простой и наглядный способ для новичка — через графический интерфейс, то есть «черепашку» (tortoise):
1. Скачать TortoiseGit
2. Установить его → Теперь, если вы будете щелкать правой кнопкой мыши в папочках, у вас появятся новые пункты меню: Git Clone, Git Create repository here, TortoiseGit
3. Перейти в папку, где у нас будет храниться проект. Допустим, это будет D:\git.
4. Нажать правой кнопкой мыши → Git Clone

Заполнить поля:
URL — https://bitbucket.org/testbasecode/folks/src/master/ (откуда выкачиваем исходный код)
Directory — D:\git\folks_tortoise_git (куда сохраняем на нашем компьютере)

5. Нажать «Ок»
Вот и всё! Система что-то там повыкачивает и покажет результат — папочку с кодом!
Итого мы получили 3 папки с одинаковым кодом! Неважно, какой способ выберете вы, результат не изменится:

Итого
Пусть вас не пугают страшные слова типа SVN, Mercurial, Git, VCS — это всё примерно одно и то же. Место для хранения кода, со всеми его версиями. Дропбокс разработчика! И даже круче =) Ведь в дропбоксе любое параллельное изменение порождает конфликтную версию.
Я храню свою книгу в дропбоксе. Там же лежит файл для художницы «TODO Вике». Когда я придумываю новую картинку, то добавляю ее в конец файла. Когда Вика заканчивает рисовать, она отмечает в ТЗ, какая картинка готова.
Мы правим разные места. Вика идет сначала, я добавляю в конец. Казалось бы, можно сохранить и ее, и мои изменения. Но нет, если файл открыт у обеих, то при втором сохранении создается конфликтная копия. И надо вручную синхронизировать изменения.
Гуглодок в этом плане получше будет, его можно редактировать параллельно. И если менять разные места, конфликтов совсем не будет!
Но сравнивать с гуглодокой тоже будет неправильно. Потому что гуглодоку можно редактировать параллельно, а в VCS каждый работает со своей версией файла, которую скачал с хранилища. И только когда разработчик решил, что «пора» — он сохраняет изменения обратно в хранилище.

Когда вы приходите на новую работу, вам нужно выкачать код из хранилища. Это означает просто забрать из общего хранилища актуальную версию. Как если бы вы зашли в дропбокс и скопипастили себе последнюю версию файлов. Просто в VCS это делается при помощи командной строки или специального графического интерфейса типа Tortoise Hg.

Это нестрашно =) Посмотрите выше пример — буквально 1 команда позволяет нам получить этот самый код.
А потом уже, если разрешат, вы сможете даже вносить свои изменения — в основной код или код автотестов. Но если уж вы с этим справитесь, то с коммитом и подавно!
PS — это выдержка из моей книги для начинающих тестировщиков, написана в помощь студентам моей школы для тестировщиков
Добрый день.удивительно, но эту статью я прочитал два дня назад в телеграмм
ОтветитьУдалитьА что удивительного?) На хабре я публикую раньше, чем в блоге, наоборот нельзя правилами хабра
Удалить