Чтобы понимать, какие запросы можно отправлять в GraphQL API и что можно получить в ответе, нужно уметь читать его схему. Это как WSDL в SOAP API — описание всех доступных методов.

Да, программы типа Postman или Apollo сами считывают схему и показывают вам всё в красивом виде — просто ходи да «натыкивай» запросы. Но если само API ещё в разработке, чтение схемы поможет понять, что вас ожидает.
Поэтому в этой статье я расскажу, что такое Schema GraphQL API и как её читать.
Что такое схема и что там есть
Схема содержит:
данные, которые мы можем получить в ответе;
доступные запросы (query и mutation).
Описывается по schema definition language (SDL). И выглядит примерно как несколько идущих подряд JSON-объектов. Так что, если знакомы с форматом JSON, схему тоже прочитать сможете!
См также:
По сути своей схема — это ТЗ. Когда нужно создать GraphQL API, аналитик размышляет, какую информацию туда выводить, и пишет схему. Скажем, у нас есть список книг (только их названия для простоты) и нужен метод для получения этого списка. Схема будет выглядеть примерно вот так:
type Book {
title: String
}
type Query {
getAllBooks: [Book]
}
Теперь вспомним, что схема содержит, и что можно понять, читая её:
данные, которые мы можем получить в ответе — объект книги Book, его поле title;
доступные запросы (query и mutation) — только запросы типа query. И у нас будет всего 1 запрос: getAllBooks.
Что и делает разработчик, добавляя обвязку в коде, которая даст возможность получать всю эту информацию.
Соответственно, схема — идеальное ТЗ, которое всегда актуально. Ведь здесь невозможно сделать описание, как в «обычных», привычных нам soap или rest методах, где есть четкое «что на входе» и не менее четкое «что на выходе».
В GraphQL формат вывода данных более гибкий. Чтобы описать, что именно можно попросить на входе, нужно будет для каждого метода делать копипасту со схемы. А это трудозатратно и неэффективно — если что-то изменится, нужно исправлять во всех местах?
Проще дать общее описание методов и их логики + ссылку на схему. Поэтому давайте посмотрим, что мы можем найти в схеме.
Объекты, с которыми мы будем работать
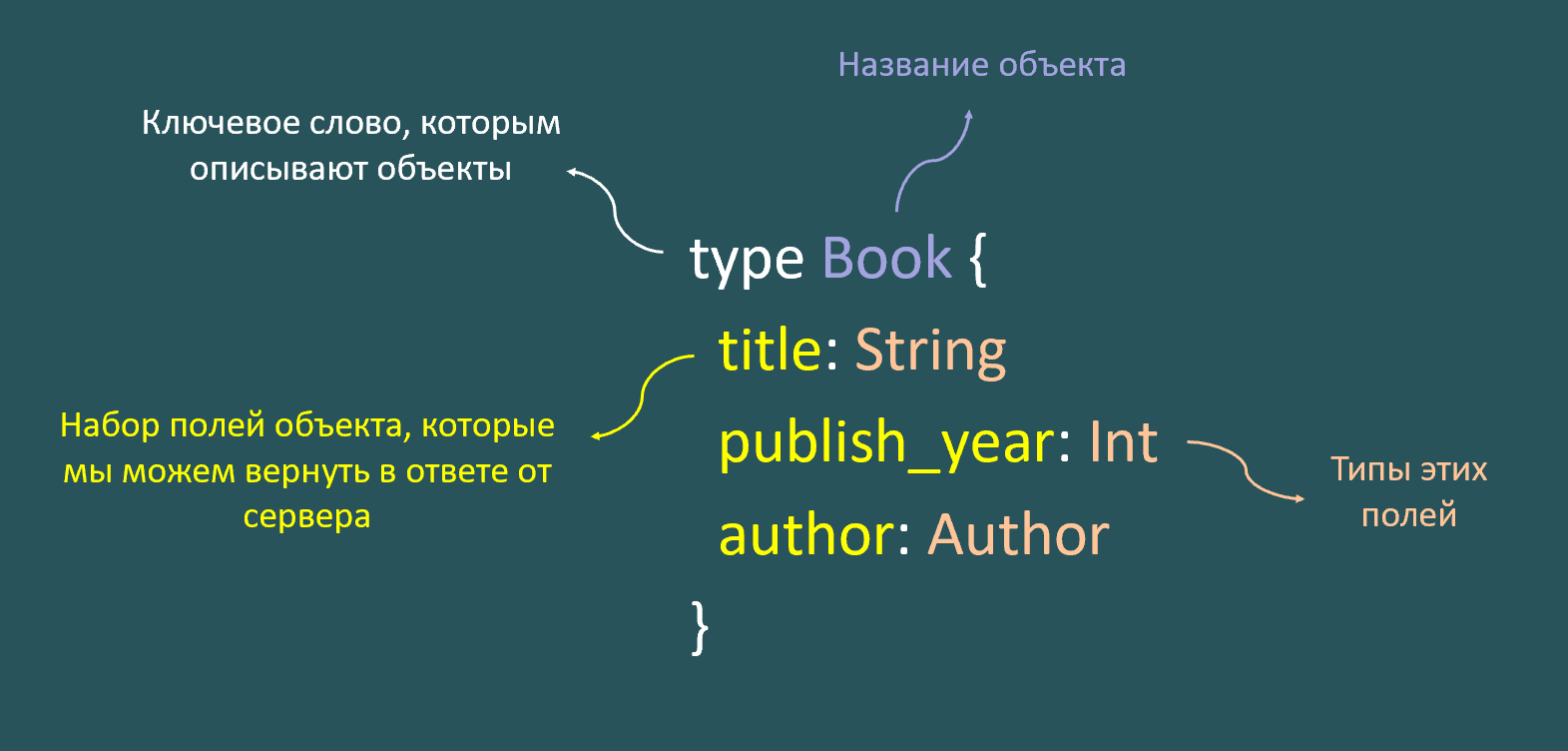
Объекты в схеме описываются через ключевое слово type. Общий синтаксис:
Ключевое слово type
Название объекта
Внутри фигурных скобок — набор полей объекта и их типов (через двоеточие, название поля: его тип)
Если какой-либо метод возвращает объект (сам по себе, или через связанный объект) — мы можем вернуть в ответе любое из его полей.
Подробнее про типы полей, которые встречаются в объекте, см ниже.
Аргументы внутри объекта
У любого поля объекта (который создается с помощью type) могут быть аргументы. То есть такая запись тоже нормальная:
type Author {
name: String
books(limit: Int): [Book]
}
Хотя обычно аргументы используют внутри запросов и мутаций (это ведь тоже объекты, которые создаются через type):
type Query {
getBook(id: ID!): Book
}
type Mutation {
createBook(id: ID!, title:String!): Book
}
См также:
Аргументы внутри объекта Schema GraphQL — для чего нужны — подробнее разберем, зачем это нужно в простом объекте, а не запросе / мутации.
Запросы и мутации
По сути своей запрос или мутация — это тоже объект. Поэтому начинаются они с ключевого слова type. Разница только в том, что идет внутри фигурных скобок:
Простой объект — название поля: его тип данных.
Запрос или мутация — название метода: то, что он возвращает в ответ.
Вот, например, как может выглядеть схема, где мы возвращаем все книги и всех авторов (в разных запросах):
type Query {
books: [Book]
authors: [Author]
}
Здесь у нас в типе Query (запрос) есть два метода — books и authors. Теперь, при наличии такой схемы, мы можем вызвать любой из этих методов, например:
query {
authors {
name
}
}
}
Как именно назвать метод — решает разработчик. Он может дать и привычные глазу названия:
type Query {
getAllBooks: [Book]
getAllAuthors: [Author]
}
Тогда при вызове метода мы будем указывать уже getAllAuthors:
query {
getAllAuthors {
name
}
}
}
Но это не является каким-то обязательным требованием. Как захотел — так и назвал.
И помните, что по сути своей название метода — это просто поле объекта Query (или Mutation). Соответственно, у него могут быть аргументы:
type Query {
getBook(id: ID!): Book
}
В мутации всё делается по аналогии, разве что аргументов там обычно сильно больше, особенно в методах создания сущности:
type Mutation {
createBook(id: ID!, title:String!, desc:String, author: Author, publish_date: String): Book
}
Есть ещё один вариант методов — Subscriptions (подписки). В схеме они описываются аналогично запросам и мутациям.
Массивы и обязательные поля
Если у поля стоит «!» — оно обязательное. И мы ожидаем, что сервер будет возвращать ненулевое значение. Восклицательный знак ставится в схеме после указания типа данных поля:
type User {
name: String!
age: Int
}
Ненулевым может быть не только само поле, но и какой-то его аргумент. Если в запросе есть ненулевой аргумент — его обязательно надо указать, иначе получим ошибку. В схеме ставим «!» после типа данных аргумента:
type Query {
getUser(id: ID!): User
}
Массив — это набор значений. Он указывается в схеме через квадратные скобки, как и массив в json. Допустим, что у книги есть поле с её цветом (colors) — она может быть цветная, может быть черно-белая, но могут быть и оба варианта. Тогда указываем массив:
type Book {
title: String!
author: Author!
colors: [String]!
}
А как ставятся восклицательные знаки у массивов? Тут есть разные варианты:
1. Непустое значение внутри массива
Массив может быть пустым, но если внутри что-то есть, то непустое!
В схеме это записывается так:
colors: [String!]
+ Допустимые варианты ответа:
colors: null
colors: []
colors: ["Цвет", "Ч/б"]
- Недопустимые варианты:
colors: ["Цвет", null, "Ч/б"]
2. Обязательный массив, но могут быть пустые значения внутри
В схеме это записывается так:
colors: [String]!
+ Допустимые варианты ответа:
colors: []
colors: ["Цвет", "Ч/б"]
colors: ["Цвет", null, "Ч/б"]
- Недопустимые варианты:
colors: null
3. Обязательный массив без пустых значений
В схеме это записывается так:
colors: [String!]!
+ Допустимые варианты ответа:
colors: []
colors: ["Цвет", "Ч/б"]
- Недопустимые варианты:
colors: null
colors: ["Цвет", null, "Ч/б"]
Соберем всё вместе для наглядности:

Комментарии
SDL (schema definition language) поддерживает добавление комментариев. Куда же без них?
Комментарии начинаются с символа «#» и могут идти как перед какой-то строкой, так и сразу после неё:
# Книги, выпущенные нашим издательством
type Book {
title: String!
author: Author
publish_date: String! # Дата может быть указана как просто годом, так и «Июль 2020», поэтому делаем просто строкой
}
Все, что следует за символом «#» на той же строке, будет игнорироваться парсером GraphQL.
Если нужен многострочный комментарий, используются тройные кавычки:
"""
Тут был
Ооооооочень длинный
Комментарий
"""
type Book {
title: String!
author: Author
}
Документация
Тройные кавычки используются для многострочных комментариев и документации. Их уже парсер не игнорирует, а наоборот.
Некоторые инструменты (например, Apollo) могут автоматически извлекать комментарии, заключенные в тройные кавычки, для генерации документации.
И если у нас такая схема:
""" Книги, выпущенные нашим издательством """
type Book {
""" Название книги """
title: String!
""" Автор книги """
author: Author
}
То при натыкивании запроса система будет давать подсказки к полям:
title — Название книги
author — Автор книги
См также:
Документация в Apollo по методам GraphQL — откуда берется
Типы данных в схеме
Object (type)
Объект — коллекция полей и их типов. Записывается почти как в json — элементы коллекции идут внутри фигурных скобок, только не разделяются запятыми.
Сами элементы зависят от того, что за объект:
Простой объект (любое название, кроме Query и Mutation) — название поля: его тип данных.
Запрос или мутация — название метода: то, что он возвращает в ответ.
Объект может включать в себя другой объект.
Например, есть такой кусок схемы:
type Book {
title: String
author: Author
}
type Author {
name: String
books: [Book]
}
В объекте книги (Book) есть поле автора — и это ссылка на объект «Автор» (Author).
В объекте автора (Author) есть поле «книги автора» — и это массив объектов «Книга» (Book).
Если один объект включает в себя другой, то элементы «дочернего» объекта можно вызвать в запросе. Если у нас есть запрос с названием getAllBooks, который получает список всех книг, мы можем запросить в ответе и название книги, и имя её автора:
query {
getAllBooks {
title
author {
name
}
}
}
А ещё в каждом объекте есть поле «__typename»! Его не надо прописывать в схеме отдельно, оно есть по умолчанию. Это поле возвращает тип объекта. Например, для приведенной выше схемы мы можем вызвать такой запрос:
query {
getAllBooks {
title
__typename
author {
name
__typename
}
}
}
Ответ будет такого плана:
"data": {
"getAllBooks": {
"title": "Книга",
"__typename": "Book",
"author": {
"name": "Петр Иванов",
"__typename": "Author"
}
}
}
}
Это поле помогает нам понять, где мы находимся в данный момент, на каком уровне вложенности — ведь у нас может быть объект в объекте внутри объекта, и так хоть 10 раз!
Scalar
Scalar — аналог примитивных типов в языке программирования:
Int — целочисленное значение
Float — дробное значение
String — строка
Boolean — true или false
ID — идентификатор
В этом примере схемы:
type Book {
title: String
author: Author
}
Поле «title» у книги — это скалярный тип, простая строка (String). Это базовые типы, их будет много в схеме: строки, числа…
Можно сделать свой тип данных: custom scalar type. Он нужен, когда нам нужно сделать доп проверки вокруг базовых типов. Например:
Date — чтобы это была не просто строка, а именно дата
URL — вроде строка, но там гарантированно корректный URL
ODD — только нечетные числа Int
…
Как это выглядит в схеме:
scalar MyCustomScalar
scalar Date
И всё, используем дальше этот тип там, где может быть другой скалярный тип (тип поля объекта, тип аргумента):
type Book {
title: String!
author: Author
publish_date: Date!
}
А остальное делается в коде разработчиком.
Input
Input — специальный тип объекта, позволяет использовать иерархические данные в аргументах.
Например, у нас в системе хранятся пользователи и их банковские карты. Если я хочу создать пользователя сразу с картами, как бы мне эти самые карты указать? Тут есть варианты — или внутри мутации указывать просто набор полей (банк, номер карты, баланс), или соединить их вместе и вынести в инпут.
Это будет выглядеть как-то так:
type Mutation {
addUserWithCards(name: String!, age: Int, cards: [CardInput]): User!
}
Input CardInput {
bank: Bank
number: String
balance: Float
}
Name, age — простые типы, их можно использовать в качестве аргументов.
Cards — иерархический тип: у него не одно поле, а несколько. Вот для его описания и нужен Input! Потому что просто написать фигурные скобки объекта внутри аргумента нельзя.
Внутри Input могут быть только скалярные типы, enum или другой input. То есть если нужен объект в объекте, создаем несколько input и вкладываем один в другой! Например:
input BlogPostContent {
title: String
body: String
media: [MediaDetails!]
}
input MediaDetails {
format: MediaFormat!
url: String!
}
enum MediaFormat {
IMAGE
VIDEO
}
Enum
Enum — перечисление корректных значений для заданного поля. Никакие другие значения это поле принимать / возвращать не будет. Это как выпадающий список в GUI — там можно выбрать одно из заданных в списке значений, но ввести своё нельзя.
Например, у нас есть такой список цветов:
enum Color {
RED
GREEN
BLUE
}
Допустимы только 3 цвета: красный, зеленый, синий. Ввести желтый (YELLOW) нельзя!
Enum — простой тип данных, как скаляр, используется везде, где и скаляр (в объектах, инпутах, в аргументах)
Union
Union — абстрактный тип, который позволяет возвращать в поле один из нескольких типов объектов. Это как UNION в SQL.
Union перечисляет, какие объекты он может возвращать. Например, я делаю поиск в книжном магазине. В строку поиска я могу ввести как название книги, так и имя автора, и ожидаю увидеть или книги, или карточку автора.
В схеме это записывается через Union:
union SearchResult = Book | Author
type Book {
title: String!
}
type Author {
name: String!
}
type Query {
search(contains: String): [SearchResult!]
}
Но тут возникает вопрос — А как мне перечислять, какие поля я ожидаю в ответе?
Для этого в запросе используется синтаксис с многоточием (... on TypeName).
В нашем примере запрос будет выглядеть примерно так:
query {
search(contains: "Пушкин") {
__typename
... on Book {
title
}
... on Author {
name
}
}
}
Писать «__typename» необязательно, но крайне желательно, чтобы точно понимать, где что вернулось.
Пример ответа на такой запрос:
{
"data": {
"search": [
{
"__typename": "Book",
"title": "Сказки Пушкина"
},
{
"__typename": "Author",
"name": "Пушкин"
}
]
}
}
Interface
Interface (интерфейс) — абстрактный тип, он задает набор полей, которые могут иметь разные объекты.
И если объект имплементирует интерфейс, он обязан содержать все поля из этого интерфейса. Но при этом у него могут быть и свои уникальные поля.
Таким образом, если нам нужно сделать несколько похожих друг на друга объектов, то вместо копипасты одинаковых полей лучше вынести их в интерфейс:
interface Book {
title: String!
author: Author!
}
type Textbook implements Book {
title: String!
author: Author!
id: ID
}
type ColoringBook implements Book {
title: String!
author: Author!
colors: [String!]!
}
type Query {
books: [Book!]!
}
В данном примере у нас есть:
Book — интерфейс, который задает стандартный для всех типов книг набор полей
Textbook — текстовая книга, так как имплементирует интерфейс, то содержит его поля + свои (id)
ColoringBook — также имплементирует интерфейс, поэтому есть все поля интерфейса + собственное поле colors
Интерфейс можно возвращать в запросе. В данной схеме мы видим Query.books — этот запрос возвращает список, в котором могут быть как Textbook, так и ColoringBook.
В ответе от сервера мы можем возвращать все поля интерфейса и поля из конкретных объектов, его имплементирующих.
Запрос для общих полей:
query GetBooks {
books {
title
author
}
}
Чтобы указать поля конкретного объекта, используется синтаксис с многоточием (... on TypeName), как в Union.
Запрос, учитывающий особенности разных объектов (опять же, поле «__typename» крайне рекомендуется, с ним будет проще читать ответ):
query GetBooks {
books {
__typename
title
... on Textbook {
id
}
... on ColoringBook {
colors
}
}
}
Пример ответа:
{
"data": {
"books": [
{
"__typename": "Textbook",
"title": "Тест-дизайн",
"id": "aaaa-1234-bbbb-3333"
},
{
"__typename": "ColoringBook",
"title": "SQL",
"colors": ["Цвет", "Ч/б"]
}
]
}
}
Итого
Если вы сталкивались с JSON-форматом, то прочитать схему GraphQL API не составит труда. А ведь из неё можно узнать много полезной информации.
Тем более что схема — это самое самое актуальное ТЗ. И даже если в «официальной» документации метода что-то устарело, можно обратиться в схеме и узнать из неё, как это работает.
Поэтому уметь читать схему полезно. Надеюсь, эта статья вам в этом хоть немного поможет =))
См также (полезные статьи про схему на англ языке в официальной документации):
Schemas and Types (graphql.org)
GraphQL Schema Basics (apollographql)
Комментариев нет:
Отправить комментарий