Хочу поделиться историей из жизни, какую задачку я сегодня решала грепом, как у меня не работала регулярка и как именно я её отлаживала =)
Тестирую загрузку ГАР (справочник адресов от налоговой) в нашу систему. Для этого изучаю сам справочник. Он разбит по папкам-регионам, и в каждом набор файликов — дома, улицы, квартиры... Все они ссылаются на reestrobj, поэтому с этого файлика я и начала.
Для начала хочется посмотреть на данные, как они выглядят. Но как это сделать, если файлики весят слишком много и простой блокнот просто зависнет при попытке открыть reestrobj для Москвы или даже Адыгеи?
Тут есть 2 варианта:
- Сделать grep — выцепить первые 2000+ строк в отдельный файл. Потом открыть спокойноблокнотом и изучить
- Открыть файл мелкого региона, где мало данных.
Пойдем сначала по второму пути. Погуглим «гар коды регионов» — вот какая отличная статья попалась! Тут сразу видно, сколько весит каждый регион.
Ага, регион 08 весит мало, попробуем открыть его.
Смотрим в распакованном ГАР, и правда, не очень много:

Запихиваем этот файлик в Идею (IDEA — среда разработки), пока выглядит не ахти:

Реформат кода сделать нельзя, потому что файл слишком большой… Чтож, пойдем по пути грепа!
У меня винда, поэтому для грепа я использую cygwin
При установке проверяем, что пакет grep включен. Дальше гугл в помощь:
«grep первые n строк». А, так греп там и не нужен, делаем так:
head -500 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML > reestr_obj_500.xml
Командой «head -500» мы вытащили из файла AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML первые 500 строк.
А с помощью « > reestr_obj_500.xml» сохранили результат в отдельный файлик.
Вот только он тоже слишком большой, те же 23мб…
Ладно, тогда так:
head -200 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML > reestr_obj_200.xml
Снова 23 мб, хм… А 10?
head -10 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML > reestr_obj_10.xml
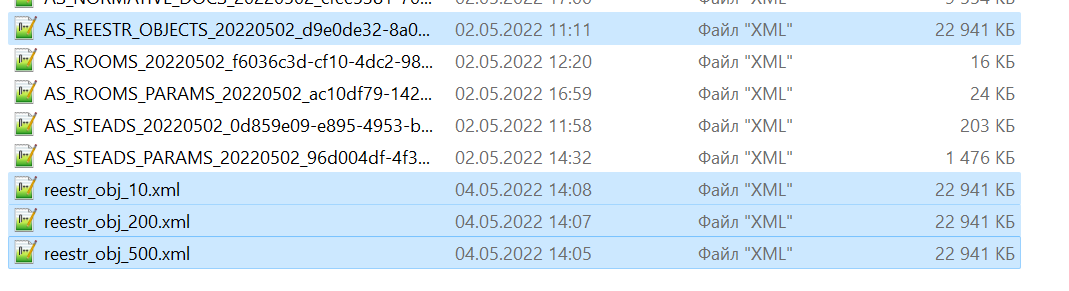
Отстой. Попробовала выцепить 1 строку прямо в консоли:
head -1 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML
И опять получила простыню текста. Блин, там похоже всё одной строкой запихали.
Ушла гуглить «вывести первые N символов файла», наткнулась на команду cut. Точно!
cut -c -10 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML
Вроде работает. Теперь нам надо много символов и в файл отдельный:
cut -c -10000000 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML > reestr_obj_small.xml
См также: https://losst.ru/komanda-cut-linux — о команде
Ага! В файле 9766 кб размер, уже лучше! Откроем в Идее — ну, так оно хотя бы читаемо стало:
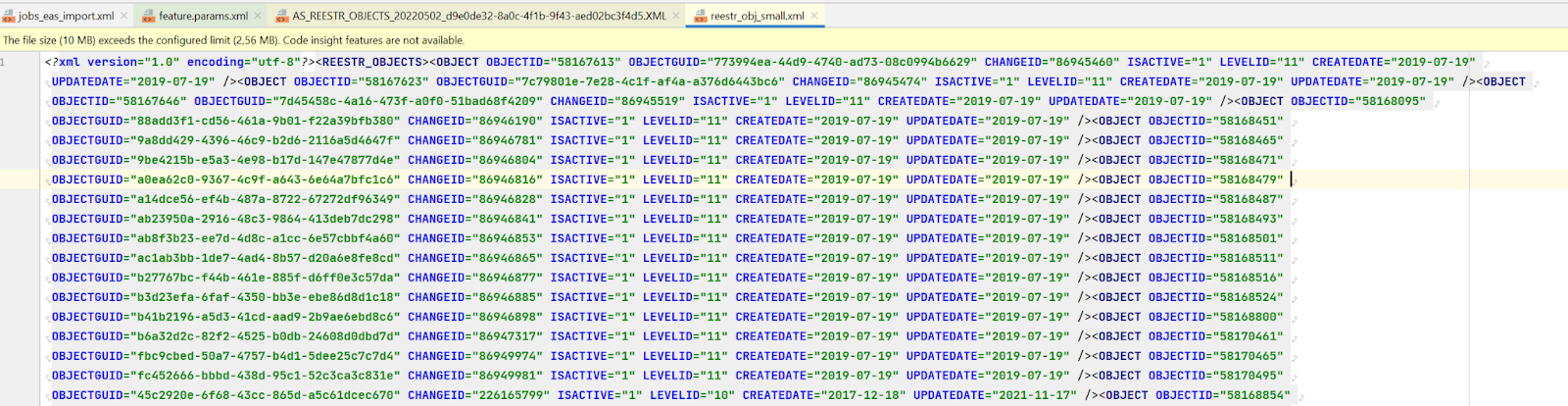
Что мы там видим? Объекты выглядят примерно так:
<OBJECT OBJECTID="67534109" OBJECTGUID="0720a711-8aba-4e30-9a8d-40ed157098ff" CHANGEID="100684887" ISACTIVE="1" LEVELID="11" CREATEDATE="2019-07-19" UPDATEDATE="2019-07-19" />
А дальше я хочу убедиться, что в ГАР других вариантов записи объекта нет. Тут можно сделать регулярку “как объект выглядит” и поискать всё, что под неё не подходит. Я думала, это легко и быстро, но оказалось не так =)
Пишем регулярку для grep
Сначала напишем регексп «как объект правильно выглядит».
Для отладки я использую сайт https://regex101.com/
Вставим туда один объект отдельно + пару объектов как в реальном файле (слитно в одну строку):
<OBJECT OBJECTID="9202641" OBJECTGUID="bd86d71d-71af-41a5-9e38-67a4b374483d" CHANGEID="224898726" ISACTIVE="0" LEVELID="10" CREATEDATE="2011-11-24" UPDATEDATE="2021-11-09"/>
<OBJECT OBJECTID="115726" OBJECTGUID="b9b6a786-05c3-461b-8f5f-45e949ec8564" CHANGEID="193505191" ISACTIVE="1" LEVELID="6" CREATEDATE="2015-09-02" UPDATEDATE="2021-05-27" /><OBJECT OBJECTID="115775" OBJECTGUID="94e9a2fc-0c50-40e8-8a27-d43fd35d9e6f" CHANGEID="193505209" ISACTIVE="1" LEVELID="6" CREATEDATE="2015-09-02" UPDATEDATE="2021-05-27" />
И сделаем регулярку. Как писать регулярку? Идем от простого к сложному, потихоньку её расширяя:
<.*\/> — пока просто проверили открывающий и закрывающий тег.
Что внутри, неважно (.*). При этом регулярка захавала оба объекта из
реального примера, где все теги в одну строку идут. Ну ничего, это мы скоро отсеем.
Добавим OBJECTID:
<OBJECT OBJECTID="\d*".*\/>
Потом все остальные элементы:
<OBJECT OBJECTID="\d*" OBJECTGUID="\w*-\w*-\w*-\w*-\w*" CHANGEID="\d*" ISACTIVE="[01]" LEVELID="\d+" CREATEDATE="\d{4}-\d\d-\d\d" UPDATEDATE="\d{4}-\d\d-\d\d"\s*\/>
Пошли потестим! В грепе есть опция -c, которая считает количество вхождений шаблона.
Затестим на мелком файле вначале. Сделаем мелкий:
cut -c -10000 AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML > reestr_obj_100.xml
Он всего 10 кб весит. А ну-ка:
grep -c "<OBJECT OBJECTID="\d*" OBJECTGUID="\w*-\w*-\w*-\w*-\w*" CHANGEID="\d*" ISACTIVE="[01]" LEVELID="\d+" CREATEDATE="\d{4}-\d\d-\d\d" UPDATEDATE="\d{4}-\d\d-\d\d"\s*\/>" reestr_obj_100.xml
0, хммм… Вставим этот файл в https://regex101.com/ — там 57 совпадений.
Экранируем угловые скобки
grep -c "\<OBJECT OBJECTID="\d*" OBJECTGUID="\w*-\w*-\w*-\w*-\w*" CHANGEID="\d*" ISACTIVE="[01]" LEVELID="\d+" CREATEDATE="\d{4}-\d\d-\d\d" UPDATEDATE="\d{4}-\d\d-\d\d"\s*\/\>" reestr_obj_100.xml
Всё равно 0. Ок, проверим первый вариант, простой
grep -c "<.*\/>" reestr_obj_100.xml
Работает! 1 вхождение нашел… Ага, тогда дело в кавычках внутри, давайте их экранируем
grep -c "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*\/>" reestr_obj_100.xml
Ноль… Снова пойдем от простого:
grep -c "<OBJECT OBJECTID=\"\d*\".*\/>" reestr_obj_100.xml
0…
grep -c "<OBJECT .*\/>" reestr_obj_100.xml
Так нашел… Хмммм… А ты кавычку вообще найдешь, дорогой?
grep -c ".*\".*" reestr_obj_100.xml
Найдешь… А \d умеешь?
grep -c ".*\d.*" reestr_obj_100.xml
Умеешь… Ладно, пойдем потихоньку:
grep -c "<OBJECT OBJECTID=.*\/>" reestr_obj_100.xml — ок, работает
grep -c "<OBJECT OBJECTID=\".*\/>" reestr_obj_100.xml — работает
grep -c "<OBJECT OBJECTID=\"\d.*\/>" reestr_obj_100.xml — не работает
grep -c "<OBJECT OBJECTID=\"5.*\/>" reestr_obj_100.xml — работает… Мммм…
Пошла в чат к коллегам-разработчикам, расписала вопрос “так работает, так нет”.
Коллега говорит:
— Попробуй [[:digit:]]
Первая реакция “да зачем, я же \d отдельно проверяла!”. Но пошла и попробовала:
grep -c "<OBJECT OBJECTID=\"[[:digit:]].*\/>" reestr_obj_100.xml — работает о_О
Ооооооок… Перепишем остальное (не ручками, конечно же, в блокноте автозамену сделала)
grep -c "<OBJECT OBJECTID=\"[[:digit:]]*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"[[:digit:]]*\" ISACTIVE=\"[01]\" LEVELID=\"[[:digit:]]+\" CREATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\" UPDATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\"\s*\/>" reestr_obj_100.xml
Не работает. Штош, заменим и \w на [[:word:]]
grep -c "<OBJECT OBJECTID=\"[[:digit:]]*\" OBJECTGUID=\"[[:word:]]*-[[:word:]]*-[[:word:]]*-[[:word:]]*-[[:word:]]*\" CHANGEID=\"[[:digit:]]*\" ISACTIVE=\"[01]\" LEVELID=\"[[:digit:]]+\" CREATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\" UPDATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\"\s*\/>" reestr_obj_100.xml
grep: Invalid character class name
Да ну тебя нафиг, OBJECTGUID будет любым
grep -c "<OBJECT OBJECTID=\"[[:digit:]]*\" OBJECTGUID=\".*\" CHANGEID=\"[[:digit:]]*\" ISACTIVE=\"[01]\" LEVELID=\"[[:digit:]]+\" CREATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\" UPDATEDATE=\"[[:digit:]]{4}-[[:digit:]][[:digit:]]-[[:digit:]][[:digit:]]\"\s*\/>" reestr_obj_100.xml
Не сработало… Ладно, коллега сказал, почему у меня \d не сработало:
— Вот что гУгл говорит: режим grep умолчанию - (iirc) POSIX regex, а \d - pcre.
Ушла гуглить синтаксисы, нашла эту статью, дальше пошла гуглить «как переключить grep на PCRE», нашла эту статью про флаг -P. А ну-ка:
grep -Pc "<OBJECT OBJECTID=\"\d.*\/>" reestr_obj_100.xml — работает!
Ну-ка, ну-ка:
grep -Pc "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*\/>" reestr_obj_100.xml
Нашлось 1 срабатывание, ура! Теперь осталось понять почему одно… На сайте их 57
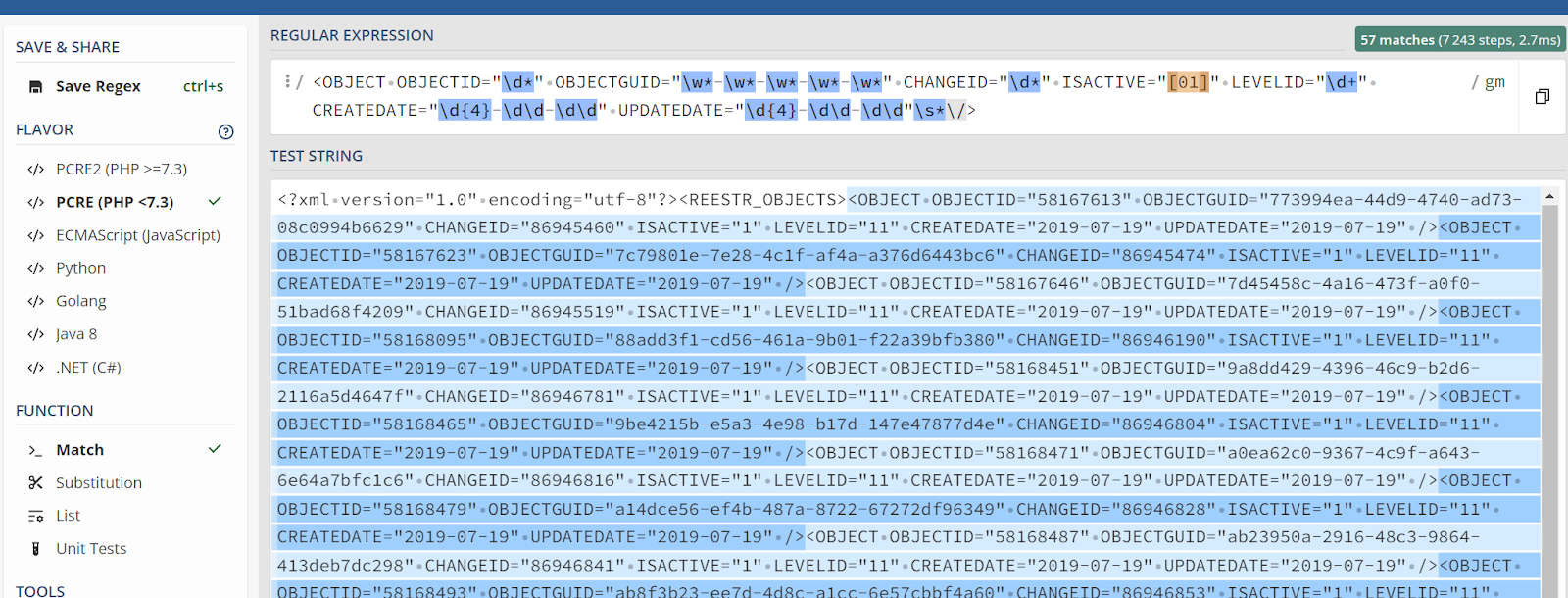
Получается, какой-то квантификатор у меня стал жадным, но какой? Может, последний?
Сделаем его ленивым: \s*?
grep -Pc "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*?\/>" reestr_obj_100.xml — неа, всё равно 1
А если так
grep -Pc "<.*?\/>" reestr_obj_100.xml
Тоже 1, блин. А что, если по простому слову посчитать?
grep -Pc "OBJECTGUID" reestr_obj_100.xml — 1
grep -c OBJECTGUID reestr_obj_100.xml — 1
Блин, похоже опция -c считает количество строк с вхождением, а не просто вхождений.
Проверим — скопировала файлик в reestr_obj_4.xml и там разбила одну строку на 4 энтером,
остальное выкинула. Считаем:
grep -c OBJECTGUID reestr_obj_4.xml — 4, ну огонь
Ушла общаться с разработчиком, он снова советует:
— Попробуй ключ -o
— Ключ работает:
grep -o OBJECTGUID reestr_obj_100.xml
— Вот так пробуй
grep -oP <шаблон> | wc -l
wc -l → подсчет количества строк
— grep -o OBJECTGUID reestr_obj_100.xml | wc -l
57
РАБОТАЕТ!
Теперь вернемся к нашему варианту:
grep -oP "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*?\/>" reestr_obj_100.xml | wc -l
57
Ура! Пошли посчитаем в реальном файле
grep -oP "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*?\/>" AS_REESTR_OBJECTS_20220502_d9e0de32-8a0c-4f1b-9f43-aed02bc3f4d5.XML | wc -l
134490
Но думала система при этом минут 15, и это не самый большой регион.
Хммммм, у меня исходно был план почекать исходные файлики “а есть ли там что-то,
не подходящее под шаблон”, но похоже, эту затею придется отложить,
слишком долго чекаться будут.
Разве что интереса ради на ночь оставить — вот это мысль!
Поэтому затестим опцию -v - инвертировать поиск, выдавать все строки кроме тех,
что содержат шаблон. Разумеется, отладимся на мелком файле
grep -oP "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*?\/>" reestr_obj_4.xml | wc -l
Увы, не работает. В этом случае костыль уже не спасает.
Но вообще с учетом скорости работы вариант так себе.
Пожалуй, пора переходить к автотестам и уже там проверять "а если исходный файл
плохой / битый / прочая". Хотя…
Пересеклась у кофемашины с гуру линукса, он мне напомнил про sed и подсказал команду:
— Что-то типа такого тебе разобьет построчно тэги (в данном случае сработает только на тех которые на одном уровне)
sed 's/\/></\/>\n</g' AS_OBJECT_LEVELS_20211111_4aac024d-25c4-4032-9e5b-66c69078b301.XML
А ну-ка проверим! Сделала отдельный файлик для тестов: reestr_obj_100_sed.xml. До:
sed 's/\/></\/>\n</g' reestr_obj_100_sed.xml > reestr_obj_100_sed_after.xml
После:
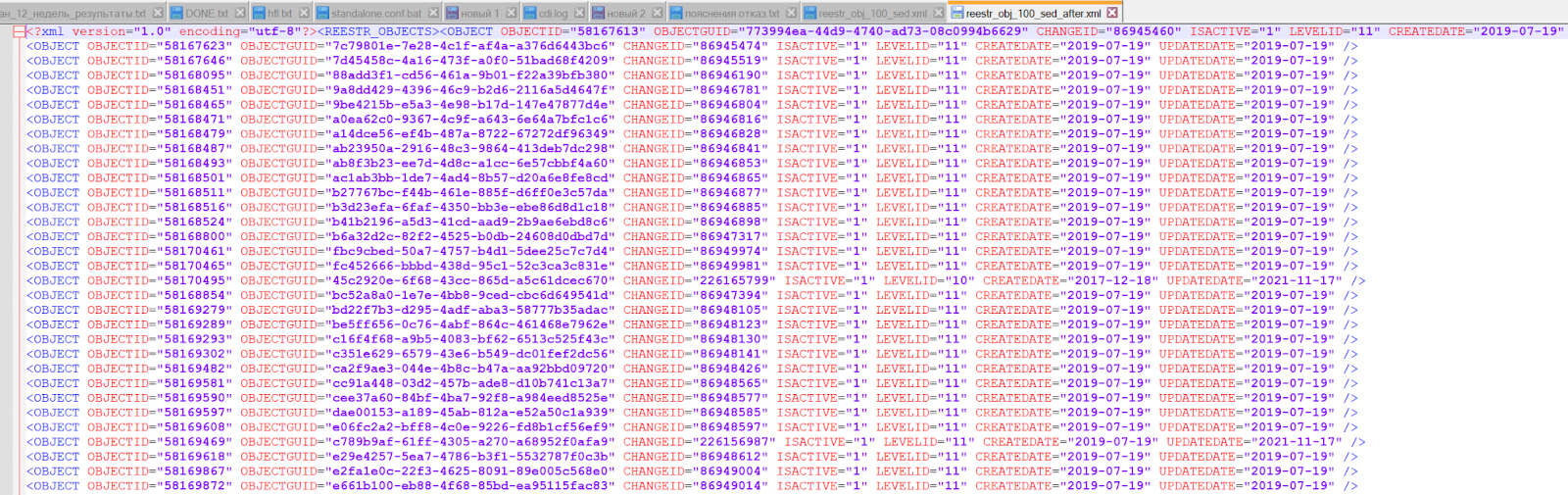
Клаааааасс. Хотя мне не очень хотелось именно корячить файлики, но для читаемости
милое дело вообще. А теперь сработает регулярочка?
grep -Pc "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*\/>" reestr_obj_100_sed_after.xml
57
Ура, работает! А с -v?
grep -Pvc "<OBJECT OBJECTID=\"\d*\" OBJECTGUID=\"\w*-\w*-\w*-\w*-\w*\" CHANGEID=\"\d*\" ISACTIVE=\"[01]\" LEVELID=\"\d+\" CREATEDATE=\"\d{4}-\d\d-\d\d\" UPDATEDATE=\"\d{4}-\d\d-\d\d\"\s*\/>" reestr_obj_100_sed_after.xml
1 (первая строка не подпадает под шаблон, так что это ок)
Как всё оказалось просто! Хотя регулярку отлаживать и так и так бы пришлось,
всё не зря получилось 😀
Комментариев нет:
Отправить комментарий