Это выдержка из моей статьи «Что такое VCS (система контроля версий)». Нужна именно как напоминание «что такое бранч», если с самой системой контроля версий вы уже знакомы
— Бранч — это отдельная ветка в коде. Вот смотрите, мы сейчас работаем в trunk-е, основной ветке.

Когда мы только-только добавили наш код на сервер, у нас появилась «точка возврата» — сохраненная версия кода, к которой мы можем обратиться в любой момент.

Потом разработчик добавляет новый функционал и коммитит его — это версия 1 кода.

Потом он добавляет еще функционал — это версия кода 2.

При этом в самой VCS сохранены все версии, и мы всегда можем:
Посмотреть изменения в версии 1
Сравнить файлы из версии 1 и версии 2 — система наглядно покажет, где они совпадают, а где отличаются
Откатиться на прошлую версию, если версия 2 была ошибкой.

Потом разработчик снова добавляет код — это версия 3.

И так далее — сколько сделаем коммитов, столько версий кода в репозитории и будет лежать. А если мы хотим сделать бранч, то система копирует актуальный код и кладет отдельно. На нашем стволе появляется новая ветка (branch по англ. — ветка). А основной ствол обычно зовут trunk-ом.

Теперь, если я захочу закоммитить изменения, они по-прежнему пойдут в основную ветку. Бранч при этом трогать НЕ будут (изменения идут в ту ветку, в которой я сейчас нахожусь. В этом примере мы создали branch, но работать продолжаем с trunk, основной веткой)
Так что мы можем смело коммитить новый код в trunk. А для показа заказчику использовать branch, который будет оставаться стабильным даже тогда, когда в основной ветке всё падает из-за кучи ошибок.
С бранчами мы всегда будем иметь работающий код!

Вы можете спросит — «Зачем эти сложности? Мы ведь всегда может просто откатиться на нужную версию! Например, на версию 2. И никаких бранчей делать не надо!».
Это верно. Но тогда нужно будет всегда помнить, в какой точке «всё работает и тут есть все нужные функции». А если делать говорящие названия бранчей, обратиться к ним намного проще. К тому же иногда надо вносить изменения именно в тот код, который на продакшене (то есть у заказчика).
Допустим, мы выпустили сборку 3, идеально работающую. Спустя неделю Заказчик ее установил, а спустя месяц нашел баг. У нас за эти недели уже 30 новых коммитов есть и куча изменений.
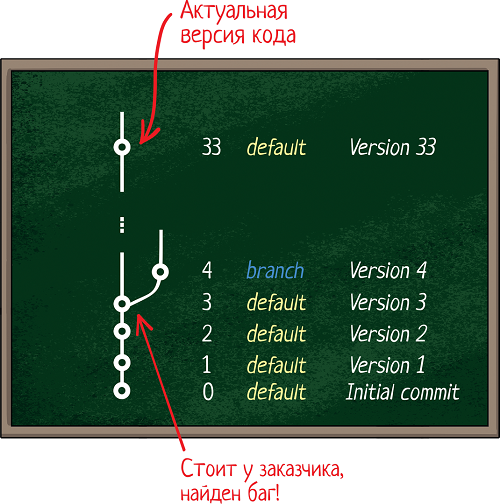
Заказчику нужно исправление ошибки, но он не готов ставить новую версию — ведь ее надо тестировать, а цикл тестирования занимает неделю. А баг то нужно исправить здесь и сейчас! Получается, нам надо:
Обновиться на версию 3
Исправить баг локально (на своей машине, а не в репозитории)
Никуда это не коммитить = потерять эти исправления
Собрать сборку локально и отдать заказчику
Не забыть скопипастить эти исправления в актуальную версию кода 33 и закоммитить (сохранить)
Что-то не очень весело. А если нужно будет снова дорабатывать код? Искать разработчика, у которого на компьютере сохранены изменения? Или скопировать их и выложить на дропбокс? А зачем тогда использовать систему контроля версий?

Именно для этого мы и бранчуемся! Чтобы всегда иметь возможность не просто вернуться к какому-то коду, но и вносить в него изменения. Вот смотрите, когда Заказчик нашел баг, мы исправили его в бранче, а потом смерджили в транк.
Смерджили — так называют слияние веток. Это когда мы внесли изменения в branch и хотим продублировать их в основной ветке кода (trunk). Мы ведь объединяем разные версии кода, там наверняка есть конфликты, а разрешение конфликтов это merge, отсюда и название!

Если Заказчик захочет добавить новую кнопочку или как-то еще изменить свою версию кода — без проблем. Снова вносим изменения в нужный бранч + в основную ветку.
Веток может быть много. И обычно чем старше продукт, тем больше веток — релиз 1, релиз 2... релиз 52...
Есть программы, которые позволяют взглянуть на дерево изменений, отрисовывая все ветки, номера коммитов и их описание. Именно в таком стиле, как показано выше =) В реальности дерево будет выглядеть примерно вот так (картинка из интернета):

А иногда и ещё сложнее!
— А как посмотреть, в какой ветке ты находишься?
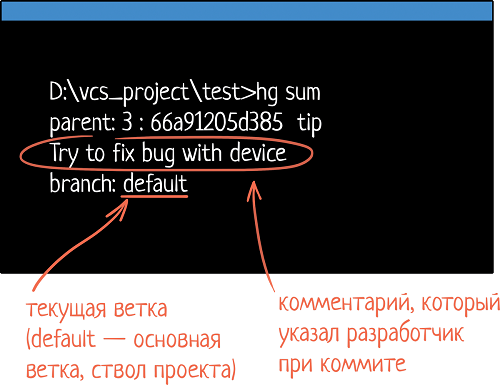
— О, для этого есть специальная команда. Например, в Mercurial это «hg sum»: она показывает информацию о том, где ты находишься. Вот пример ее вызова:
В данном примере «parent» — это номер коммита. Мы ведь можем вернуться на любой коммит в коде. Вдруг мы сейчас не на последнем, не на актуальном? Можно проверить. Тут мы находимся на версии 3. После двоеточия идет уникальный номер ревизии, ID кода.

Потом мы видим сообщение, с которым был сделан коммит. В данном случае разработчик написал «Try to fix bug with device».
И, наконец, параметр «branch»! Если там значение default — мы находимся в основной ветке. То есть мы сейчас в trunk-е. Если бы были не в нём, тут было бы название бранча. При создании бранча разработчик даёт ему имя. Оно и отображается в этом пункте.
Отдельно хочу заметить, что бранчевание на релиз — не единственный вариант работы с VCS. Есть и другой подход к разработке — когда транк поддерживают в актуальном и готовом к поставкам состоянии, а все задачи делают в отдельных ветках. Но его мы в этой статье рассматривать не будем.
PS — это выдержка из моей книги для начинающих тестировщиков, написана в помощь студентам моей школы для тестировщиков
Комментариев нет:
Отправить комментарий