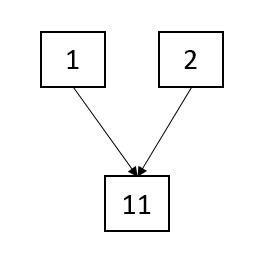
У нас можно объединять несколько карточек в одну. Вот, например, были карточки id = 1 и id = 2, которые потом объединились в id = 11.
Как это выглядит в базе данных:
1. В таблице самих карточек есть колонка Merged_status, принимает значения:
- 0 — не объединялась никогда и не результат объединения;
- 1 — объединена (id = 1 и id = 2)
- 2 — результат объединения (id = 11)
id_party
|
Merged_status
|
1
|
1
|
2
|
1
|
11
|
2
|
2. Есть отдельная табличка MERGED, в которой указано, кто, в кого и когда был объединен.
- id_party — идентификатор исходной записи, которая была объединена;
- id_final — идентификатор результата объединения;
- created — дата объединения;
- cancelled — дата разъединения (не будем вникать в технические детали, просто такое может быть и тогда она будет непустой).
Для нашего случая:
id_party
|
id_final
|
created
|
cancelled
|
1
|
11
|
15.06.2017
| |
2
|
11
|
15.06.2017
|
Задачка
Где-то в другой системе решили сопоставить свои идентификаторы и наши. Нашли случаи, когда клиент вроде как один в системах A, B, C, но у нас он не объединен. Выгрузили, получился csv файлик такого содержания
"1";"A1"
"11";"A1"
"26";"A2"
"32";"A2"
"25";"B1"
"44";"B1"
"67";"B2"
"13";"B2"
"26";"C1"
"64";"C1"
В файле 82 тысячи строк. Наша задача — проанализировать эти случаи.
Вводная
Для начала посмотрим вживую на любую из этих пар.
select * from party where id_party = 1;
-- merged_status = 1, она объединена!
select * from party where id_party = 11;
-- merged_status = 2, это результат объединения
Посмотрим, куда это 1 влился:
select * from merged where id_party = 1;
-- ага, id_final = 11
Так мы понимаем, что задача упрощается и анализировать нам надо не 82 тысячи, а меньше. Но для начала нам надо понять, сколько из этих данных устарело. Какие пары уже были объединены?
Что мы имеем?
1. Каждому ИД в колонке GROUPING соответствуют 2 id_party из нашей базы.
2. Если эта пара уже объединена, то оба ИД есть в таблице MERGED, один из которых будет id_party, а второй обязательно у него же id_final (если они объединились с разными клиентами, то это случай на ручной разбор).
3. Кто из ИД будет исходный, а кто — результат объединения, сказать на основе самого ИД нельзя. Да, идентификатор — автоинкрементальное поле, но исходный мог быть создан как до, так и после объединения. А, значит, брать мЕньший ИД нельзя.
4. Втупую взять данные из блокнота для проверки, кто исходный, а кто объединенный, тоже нельзя:
select * from merged where id_party in
(1,
11,
...
)
Получить запрос легко — копируем первую колонку в блокнот и добавляем в конец строки запятую (меняем \r\n на «,\r\n»).
Но не забываем — в файле 82 тысячи строк. А в запросе IN в оракле может быть максимум 1000 параметров. Повторять процедуру 82 раза не хочется.
Зато можно загрузить этот файл в базу и работать со временной табличкой!
5. На сервере нет SQL WorckBench, так что написать WBImport не проканает.
6. Вторая колонка в csv файле — название исходной системы + идентификатор в ней. Строка, так как названия исходных систем разные.
Напомню условие
Проанализировать csv-файл на 82 тысячи строк.
Определить:
Определить:
- сколько пар уже неактуально (объединены);
- сколько пар актуально + их список.
Итого нужны:
- SQL-скрипты для проверки в Oracle;
- Тестовые данные (вы же не пойдете фигачить сразу 82 тысячи, не проверив свои скрипты на малом объеме, правда же?)
===================================================
Это — не тестовое задание для кандидата на должность тестировщика, и я не знаю идеальный ответ ツ
Это реальная рабочая задачка. Просто она показалась мне интересной (что на что сметчить) и вот, публикую. Тем, кто учит SQL, пригодится для опыта!
Для загрузки данных из файла csv можно использовать SQL Loader, это штатная утилита оракла.
ОтветитьУдалитьУ оркала в in может быть подзапрос.
Да, спасибо, нашли в sql developer. Забавно, что гуглились только более хитрые способы...
Удалить