Да, это пост, содержащий в себе 5 предыдущих. Я хочу сохранить себе эту статью в блоггере, так как она очень крутая + мне она нужна в разбивке, чтобы я могла давать ссылки студентам точечно, а не на одну большую статью.

Ссылка на ХАБР (там кликабельное содержание, очень удобно)
Когда ручного тестировщика впервые просишь проверить метод REST API, того охватывает паника: «Как это делать? Я вообще почти ничего не знаю про API. Что делать? Как это тестировать?»
Спокойно. Без паники =) Я уже рассказывала на простом языке, что такое API. А сегодня я расскажу о том, как его тестировать. На самом деле почти также, как GUI: в первую очередь это тест-дизайн и придумывание проверок, а потом уже всякие API-штучки. Но и про них не стоит забывать.
Я дам вам чек-лист, к которому вы сможете обращаться потом — «так, это проверил, и это, и это. А вот это забыл, пойду посмотрю!». А потом мы обсудим каждый пункт — зачем это проверять и как.
После теории будет практика! Для неё возьмем метод doRegister системы Users — он находится в открытом доступе, можете дергать по ходу чтения и проверять =)
Чек-лист проверок
Общий чек-лист:
Правильное тело (пример)
Бизнес-логика: позитив, негатив
Различные параметры (обязательность, работа параметров)
Перестановка мест слагаемых (заголовки, тело)
Регистрозависимость (заголовки, тело)
Ошибки: не well formed xml / json
Где искать параметры:
В URL
В заголовках
В теле запроса
Комбинация
Тестирование параметров:
Правильный параметр (из примера)
Обязательность (что, если параметр не указать?)
Бизнес-логика (тест-дизайн)
Регистрозависимость (если параметр текстовый)
Перестановка местами
То есть берём REST-часть и обычную, применяем тест-дизайн, словно это параметр в графическом интерфейсе.
Тестирование заголовков:
Заголовки из документации работают (в целом)
А если какой-то не передать? (обязательность)
А если передать, но неправильно? (текст ошибки)
Позитивные тесты по доке
Регистронезависимость заголовков
Что смотрим в ответе:
Status Code
Body
В теле смотрим:
Какие поля вернулись в ответе?
Значения в полях
Текст ошибок
Поля в ответе нужно:
сравнить с ТЗ
сравнить между собой SOAP \ REST
Кратко прошлись, теперь разберемся в деталях и с примерами.
Позитив или негатив?
Я учу начинающих тестировщиков так: ВСЕГДА сначала позитивное тестирование, а потом негативное. Иначе вы успеете проверить всякий треш, а с нормальными данными система работать не будет.
Однако в случае тестирования интеграции негатив может оказаться приоритетнее. На одном из рабочих проектов обсуждала это с архитектором, который разрабатывает системы для интеграции — как заказное ПО, так и общедоступное. Он учил меня так:
Сначала надо проверить негатив. Потому что разработчики продукта, которые подключают наше API, всегда будут напарываться на грабли. Не прочитали документацию / прочитали криво — получили ошибку.
И нужно, чтобы по сообщению об ошибке они поняли:
— Что они сделали не так
— Как это исправить
Это нужно для того, чтобы уменьшить количество обращений в тех. поддержку.
Так что проверьте сначала всякие извращения, а потом, пока разработчик чинит найденные баги, сидите со своими позитивными тестами и позитивными сценариями.
В целом, есть логика в его словах. Ну и плюс всё зависит от времени, если вам позитивные тесты погонять займет полчасика, то проще начать с них. А если там куча сценариев + обязательные автотесты часа на 4, то можно сначала погонять руками, выдать пачку замечаний и сидеть спокойно писать свои тесты.
Обсудите со своими разработчиками, как им будет удобнее — чтобы вы сначала потыкали “на слом” и прислали очевидные баги, или вдумчиво проверили всё и прислали результат одним файлом. Как им удобнее, так и делайте.
Но лично я всё же считаю, что как минимум основной сценарий позитивный проверить надо. И желательно пару ответвлений от него.
В каком порядке тестируем
1. Примеры в ТЗ
Самое простое, что можно сделать — дернуть пример из документации, чтобы посмотреть, как метод вообще работает. А потом уже писать обвязку в коде.
Это пойдут делать тестировщики, получив от вас новый функционал. И это же сделает разработчик интеграции / другой пользователь API.
Отсюда вытекают следующие выводы:
а) Примеры в документации должны быть! Причем желательно не один, а на каждый интересный кейс. Чтобы на него точно обратили внимание!
б) Примеры тестируем в первую очередь, потому что именно их дернут первыми. И потом будут делать по аналогии.
Практика на примере Users
В Users есть только один пример:
{
"email": "milli@mail.ru",
"name": " Машенька",
"password": "1"
}Его и попробуем отправить!
Тип запроса — POST
Тело — из примера
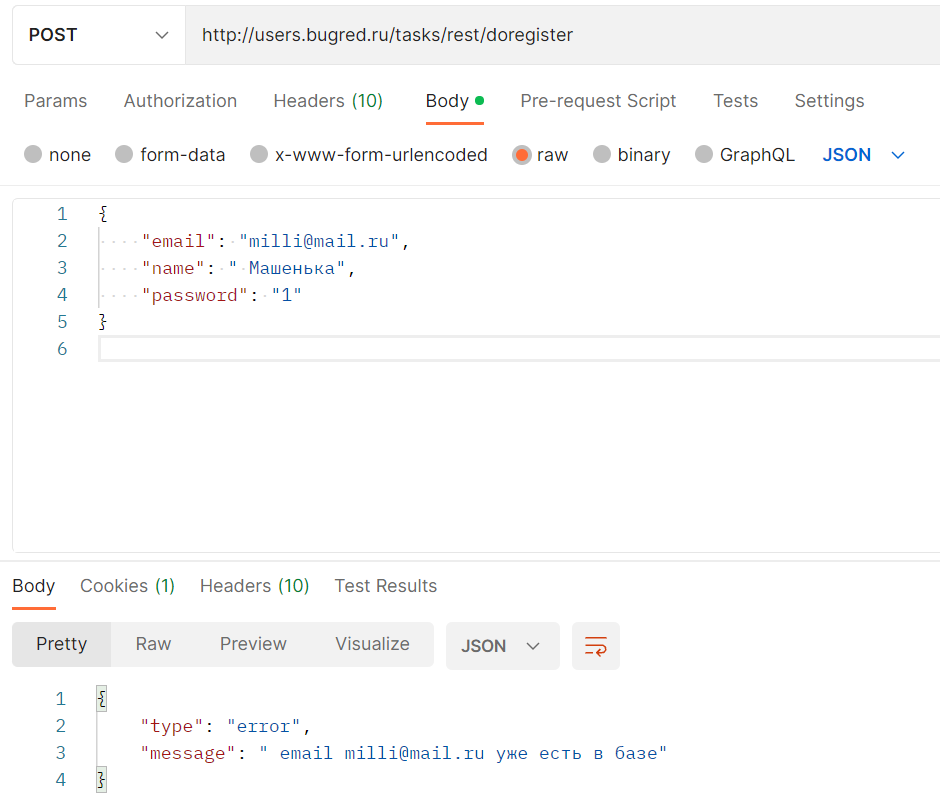
Упс, ошибочка… Читаем её внимательно:
" email milli@mail.ru уже есть в базе"В целом логично, раз метод создает нового пользователя, может быть ограничение уникальности. Смотрим в ТЗ, и правда:
Имя и емейл должны быть уникальными
Значит, метод не идемпотентный… Нельзя просто взять пример из ТЗ и отправить не глядя.
Справка
Метод HTTP является идемпотентным, если повторный идентичный запрос, сделанный один или несколько раз подряд, имеет один и тот же эффект, не изменяющий состояние сервера. Корректно реализованные методы GET, HEAD, PUT и DELETE идемпотентны, но не метод POST. © developer.mozilla.org
Нужно взять пример и отредактировать его так, чтобы данные стали уникальными. Можно от руки дописать несколько циферок:
{
"email": "milli5678@mail.ru",
"name": " Машенька5678",
"password": "1"
}А можно использовать функционал Postman, который позволяет указать рандомные значения — динамические переменные. Пожалуй, мне хватит $randomInt. Но так как я отправляю запрос в JSON-формате, то надо обернуть переменную в фигурные скобки, иначе постман считает её как простой текст:
{
"email": "milli{{$randomInt}}@mail.ru",
"name": " Машенька{{$randomInt}}",
"password": "1"
}Сработало!

Пример проверили, отлично. Он рабочий, но не идемпотентный, так что его нужно скорректировать под себя. Документация НЕ неправильная, запрос рабочий, если его прогонять на пустой базе в первый раз.
Однако пользователи бывают разные. Они вполне могут скопипастить пример, отправить его, получить ошибку и прибежать в поддержку ругаться, не читая сообщение об ошибке — у вас плохой пример, он не работает.
И чем больше у вас пользователей, тем больше таких вопросов будет. Заводить ли тут баг на правку документации? Можно предложить дописать в ТЗ как-то так:
Запрос (для проверки запроса исправьте имя пользователя и email, чтобы они были уникальными): ...
То есть заранее подсказываем, что надо изменить, чтобы запрос сработал AS IS. Можно было бы и пример с рандомными переменными постмана дать, но тут надо понимать, что через постман его будут дергать тестировщики и аналитики со стороны заказчика.
Разработчики же должны написать код, используя ваш пример. А они тоже любят копипастить))) И если дать пример, заточенный под постман, то к вам снова придут с вопросом, почему ваш пример не работает, но уже в коде. И тут опять или писать около примера, что “$randomInt — переменная Postman, она тут для того-то”, или всё же примеры оставить в покое.
Я не вижу особой проблемы в текущем описании, это не повод ставить баг на документацию. Пример нормальный и рабочий. А если принесет головную боль поддержке, тогда и замените.
В нашей доке всего 1 пример. Если бы их было больше, надо было бы вызвать все. Именно на примерах пользователи учатся работать с системой. Дернули, получили такой же ответ, изучили его, осознали, запомнили =)
2. Основной позитивный сценарий
Чтобы настраивать интеграцию, разработчику той стороны нужен работающий сценарий. Самый основной, все ответвления можно отладить позже.
В идеале он берет этот сценарий из примера. Если примеров нет, будет дергать метод наобум, как он считает правильным. Знаете, как с новым девайсом — сначала попробовал сам, если не получилось, пошел читать инструкцию.
Тем не менее у разработчика есть основной позитивный сценарий его системы, его он и будет проверять. И тестировщик должен проверить его в первую очередь.
Практика на примере Users
А у нас есть пример, так что основной позитивный сценарий мы уже почти проверили!
Почему “почти”? Мы проверили, что система вернула в ответе «успешно создалась Машенька562», но точно ли она создалась? Может быть, разработчик сделал заглушку и пока метод в разработке, он всегда возвращает ответ в стиле “успешный успех”, ничего при этом не делая.
Так что идем и проверяем, есть ли наша Машенька в GUI — http://users.bugred.ru/. Ищем поиском — есть!

Проверяем все поля:
Емейл правильный, какой мы отправляли.
Автор «rest», что логично.
Дата изменения — сегодня, что тоже правильно.
Значит, пользователь правда создан! Хотя постойте… Я же выполняла не метод CreateUser, а doRegister. Его основная цель — не создать карточку, а зарегистрировать пользователя в системе. Просто при регистрации карточка автоматом создается, поэтому её тоже зацепили проверкой.
А как проверить, что регистрация прошла успешно? Правильно, попробовать авторизоваться!
Нажимаем «Войти» и вводим наши данные: milli754@mail.ru / 1

Вошли! Ура, значит, регистрация правда сработала. Вот теперь мы закончили с основным позитивным сценарием.
3. Альтернативные сценарии
На самом деле если в ТЗ нет отдельно выделенного сценария использования, то можно объединить пункты “альтернативные сценарии” и “негативное тестирование”, потому что по факту после базового теста мы:
Читаем каждое предложение из ТЗ, «Особенности использования» или как этот раздел у вас называется
Продумываем, как его проверить: как позитивно, так и негативно.
Но давайте для чистоты эксперимента попробуем разнести эти пункты отдельно. Тогда в альтернативы попадают все дополнительные условия, которые накладываются на посылаемые или возвращаемые данные.
Практика на примере Users
Читаем особенности использования:
Пользователь создается и появляется в системе.
Это мы уже проверили. Дальше:
Автор у него всегда будет «SOAP / REST», изменять его можно только через соответствующий-метод.
Автора тоже проверили, но только вот в ТЗ он указан капсом, а по факту создается в нижнем регистре. Это уже небольшой баг, скорее всего документации, так как некритично и проще доку обновить. Сделали заметочку / сами исправили доку, если есть доступ.
А дальше видим, что изменять только только через соответствующий метод. Ага, то есть если создали через REST, менять можно тоже только через REST, через SOAP нельзя. И наоборот. Это и проверим.
Для начала под Машенькой в ГУИ посмотрим, есть ли возможность отредактировать собственную карточку — нету. Ок. Открываем в SOAP Ui WSDL проекта — http://users.bugred.ru/tasks/soap/WrapperSoapServer.php?wsdl, и смотрим, каким методом можно вносить изменения.
Нам вполне подойдет UpdateUserOneField, он обновляет одно любое поле пользователя. А как понять, какие поля есть? Покопаться в документации. В Users описаны не все методы, но есть описание CreateUser, где можно взять названия полей. Допустим, хочу обновить кличку кошки — cat. Получается запрос:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:wrap="http://foo.bar/wrappersoapserver">
<soapenv:Header/>
<soapenv:Body>
<wrap:UpdateUserOneField>
<email>milli754@mail.ru</email>
<field>cat</field>
<value>Еночка</value>
</wrap:UpdateUserOneField>
</soapenv:Body>
</soapenv:Envelope>Отправляем, хммммм:
Поле cat успешно изменено на Еночка у пользователя с email milli754@mail.ruПроверяем в интерфейсе, находим карточку пользователя и жмем “Просмотр” (прямую ссылку давать бесполезно, база дропается каждую ночь, тут только самому создать и посмотреть). Значение обновилось:

Значит, условие из ТЗ не выполнено, можно ставить баг!
А мы пока читаем дальше:
Имя и емейл должны быть уникальными
Раз должны, то будет ошибка в случае неуникальности. А мы решили вынести тестирование негативных сценариев отдельно. Видите, решение тестировать альтернативы отдельно от негативного сразу оказалось не самым удобным — куда лучше просто читать ТЗ и каждый пункт проверять. Так хоть не запутаешься, что проверил, а что ещё нет… Однако в рамках статьи мы всё-таки рассмотрим негативные тесты отдельно.
Пока же смотрим дальше — а всё, кончилось ТЗ, метод то простенький. Тогда переходим к негативу!
4. Негативные сценарии
По факту это проверка сообщений об ошибках. Смотрим на метод и думаем, как его можно сломать? Сначала бизнесово, а потом API-шно…
С бизнесовой точки зрения очень удобно, когда все ошибки прописывают прямо в ТЗ. Получается руководство к действию! Это можно быть разделение на «Особенности использования» и «Исключительные ситуации», как в Folks (логин для входа тут). Тогда тестируем блок «Исключительные ситуации».
Или вот описание Jira Cloud REST API, выберем в левом навигационном меню какой-нибудь метод, например «Delete avatar». Там есть описание метода, а потом в блоке Responces переключалки между кодами ответов.
Ну так вот все желтые коды — это ошибки. Открываем каждую, читаем «Returned if» и выполняем это условие, очень удобно:

В общем, если есть отдельно про ошибки — класс, проверяем по ТЗ. А потом ещё думаем сами, что там могло быть пропущено.
Плюс проверяем логику ошибок в API, но о ней чуть позже. Сначала бизнес-логика, потом уже серебряная пуля типа well formed json.
Практика на примере Users
Ограничение в ТЗ:
Имя и емейл должны быть уникальными
Для проверки нам надо сделать неуникальным:
имя
емейл
оба поля сразу
Можем взять за основу наш исходный запрос, который 1 раз создался:
{
"email": "milli754@mail.ru",
"name": " Машенька562",
"password": "1"
}И варьируем его
1. Уникальный емейл, дубликат имени
{
"email": "milli{{$randomInt}}@mail.ru",
"name": " Машенька562",
"password": "1"
}2. Уникальное имя, дубликат емейл
{
"email": "milli754@mail.ru",
"name": " Машенька{{$randomInt}}",
"password": "1"
}3. Дубликаты сразу имени и емейл
{
"email": "milli754@mail.ru",
"name": " Машенька562",
"password": "1"
}И смотрим на ответ. Понятно ли нам из сообщения об ошибке, что именно пошло не так? А статус-код соответствует типу ошибки?
5. Параметры запроса
На входе мы передаем какие-то параметры. И теперь нам нужно взять каждый параметр и проверить отдельно. Как проверяем:
Обязательность
Перестановка мест слагаемых
Бизнес-логика
Про первые 2 пункта мы поговорим чуть позже, сейчас сосредоточимся на бизнес-логике.
Вот у вас есть параметры запроса. Как их проверять? Если вы впали в ступор сейчас, то просто представьте себе, что это не API, а GUI. Что у вас в интерфейсе есть форма ввода с этими полями? Как будете тестировать? Вот ровно так и тестируйте, выкинув разве что попытку убрать ограничение на клиенте (снять с поля maxlenght).
Практика на примере Users
По ТЗ входные параметры:
Имя параметра | Тип | Обязательный? | Описание |
строка | да | email пользователя | |
name | строка | да | имя пользователя |
password | строка | да | пароль |
Тестируем каждый параметр в отдельности. И тут, как и в GUI, надо понимать:
Есть ли какие-то проверки у поля? Проверяется ли email по маске email-а? Имя выверяется по справочникам? Или это “просто строка, как прислали, так и сохранил?”
Куда данные идут дальше, где отображаются? В приветствии, в отчете, в личном кабинете, где?
Как они потом используются? На емейл придет письмо?
Вроде доп. проверок разработчик не делал, но точно я этого не знаю. Поле базовое, может есть прям во фреймворке какие-то проверки, или в интернете скопипастил… Так что тут стоит убедиться, что email корректный.
Можно взять за основу вот этот чек-лист, но часть проверок скомбинировать
Корректный существующий email, куда может прийти почта — подставляем свой (начинаем всегда с корректного)
Верхний регистр, цифры в имени пользователя и доменной части — TEST77@mail9.ru
Email с дефисами и нижним подчеркиванием — test_user-1@mail_test-1.com
Email с точками в имени пользователя и парой точек в доменной части — test.user@test.test.test.ru
А дальше идут интересные тесты, которые по идее должны падать, но упадут ли в Users, есть ли там такие проверки?
Email без точек в доменной части — test@mailcom
Превышение длины email (>320 символов)
Отсутствие @ в email — testmail.ru
Email с пробелами в имени пользователя — test user@mail.ru
Email с пробелами в доменной части — test@ma il.ru
Email без имени пользователя — @mail.ru
Email без доменной части — test@
Некорректный домен первого уровня (допустимо 2-6 букв после точки: .ru) — test@mail.urururururu
Помним, что имя должно быть быть уникальным при этом, потому что негативные тесты мы не смешиваем, только если в этом состоит сам тест “а что, если несколько полей сразу плохие”. Так что пример запроса:
{
"email": "test@mailcom",
"name": " Машенька{{$randomInt}}",
"password": "1"
}И сервер отвечает — некорректный емейл!

Так что проверки на емейл нужны, особенно — на некорректный.
name
Имя можно тестировать по разному. Если по нему определяется пол, тесты будут одни, если предлагаются подсказки, другие, а если это простая строка — третьи.
Так вот, в Users имя — это простая строка. Пол по ней не определяется, оно просто сохраняется в системе, разве что в правом верхнем углу отображается

Поэтому закапываться в “а теперь проверим мужское имя, и женское, и…” смысла нет.. Так что наша задача — проверить:
Что это правда простая строка и туда влезет всё, что можно
Максимальную длину изучить
Ну и начинаем с позитивного теста. Итого получаем:
Простое имя типа “Ольга”
Имя с разным регистром, разными буквами и спецсимволами (все спецсимволы можно перечислить) — если есть ограничение по длине, разобьем на разные тесты
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
1 000 000 символов — ищем технологическую границу
Обратите внимание на то, что мы вроде как тестируем API-метод, но после его выполнения лезем в графический интерфейс и проверяем, как там выглядит результат нашего запроса.
А всё почему? Потому что нет абстрактных методов, которые делают “ничего”, просто отправляются. Они все зачем-то нужны. В нашем случае — чтобы создать пользователя в системе. И важно понимать, а что будет потом с нашими данными? Будут ли они нормально отображаться в интерфейсе? Ведь если нет, то надо ставить ограничение на API-метод.
Поэтому помните, что API и GUI идут рука об руку, а не живут в разных мирах.
Password
На пароле тоже никаких ограничений нет — мы это знаем, потому что уже отправляли запрос с паролем “1”. Вот если бы были всякие “нужны заглавные буквы” и прочее, мы бы провели тесты “а если пароль ненадежный” и посмотрели на качество сообщения об ошибке, а так тесты будут как у имени:
Обычный пароль типа 1
Смесь из разных регистров, разных букв и спецсимволов — если есть ограничение по длине или составу, разобьем на разные тесты
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест.
1 000 000 символов — ищем технологическую границу
6. Остальные тесты
А дальше мы уже идем по специфике API:
Перестановка мест слагаемых (заголовки, тело)
Регистрозависимость (заголовки, тело)
Well formed xml / json
На конкретных примерах мы остановимся подробнее в следующих разделах. Просто важно не забывать про эти тесты. Этим и отличается API от GUI — тут нельзя снять границу из серии “убрать maxlenght”, зато можно и нужно проверить особенности API запросов.
Что тестируем в запросе
Заголовки (Headers)
Заголовки должны где-то обрабатываться:
— на сервере;
— на клиенте;
Иначе они не нужны, только лишний трафик гонять. Мы ведь передаем сообщение по сети, если интернет плохой, то каждый байт на счету. Зачем отправлять информацию, которую никто не использует?
Так что разработчики используют «Принцип меньшего зла»: заголовок или кем-то обрабатывается, или он вообще не нужен.
Если заголовка нет:
— используется дефолтный, прописанный в коде;
— он вообще не нужен;
Язык должен указываться всегда, иначе непонятно, как вернуть ответ от сервера. Но разработчик может в код зашить русский язык, и тогда даже если вы передадите заголовок «Accept-Language: en-US», то ответ получите на русском.
Почему? Потому что разработчик игнорирует этот заголовок, он его не считывает из запроса в принципе. Его право =)
Возможные ситуации, которые надо проверить
Заголовок не передан, как система реагирует:
— выдает ошибку → понятно ли, что мне надо сделать?
— применяет поведение по умолчанию (если язык не передан, используй русский)
Заголовок передан:
— верно
— неверно → какая ошибка?
Плюс регистрозависимость. Согласно спецификации, все заголовки должны быть регистронезависимы. И неважно, как я их передаю. Могу в CamelCase (первая буква большая, остальные мелкие), могу в верхнем регистре, причем как значение заголовка, так и его название, могу как-то ещё:
Accept: application/json
Accept: APPLICATION/JSON
ACCEPT: application/json
ACCEPT: APPLICATION/JSON
ACcePT: APPlicATIon/JSon
Проверить эти варианты — очень важно. Потому что за регистронезависимость отвечает разработчик, сама по себе из воздуха она не появится. Он должен прописать это в коде.
Был случай у моих коллег — заголовок проверили, всё работает. Но проверили по доке, прислали значения «как указано». Вот Accept может быть (как передаются входные данные):
application/json
application/xml
А потом пользователи приходят и жалуются на ошибки «у вас плохой заголовок». При том, что заголовок они отправили правильный. Начали разбираться — запрос идет не напрямую на сервер, он проходит через прокси Nginx. А Nginx меняет заголовки на upper case: ACCEPT: APPLICATION/JSON.
Система к такому не готова, она ищет «Accept», не находит его и выдает ошибку. А переданный заголовок игнорирует. Так что проверять регистр — надо!
Итого — тестирование заголовков в API
Заголовки из документации работают (в целом)
А если какой-то не передать? (обязательность)
А если передать, но неправильно? (текст ошибки)
Позитивные тесты по доке
Регистронезависимость заголовков
Практика на примере Users
В документации вообще ничего не сказано про заголовки. Поэтому проверяем, можно ли отправить сообщение без них. Идем на вкладку Headers и снимаем все галки, если они по каким-то причинам там стояли. Запрос сработал успешно:

Но обратите внимание, что в постмане есть ещё скрытые заголовки (hidden):

Это те заголовки, что генерирует сам постман. По сути постман — это клиент, помогающий нам отправить запрос на сервер. И у него есть какие-то свои фишечки, ограничения, заголовки опять же.
Можно нажать на это сообщение “(цифра) hidden” и раскрыть этот список (а потом всегда можно нажать на кнопку “hide hidden”:

Это некий стандарт, дефолтные значения по умолчанию. Тот же Cache-Control, раз вы его не передаете, по факту он вам не нужен, то есть как если бы вы указали “no-cache”.
Но учтите, что если снять тут все-все-все галки, система может выдать ошибку:

Плохо ли это? Стоит ли заводить баг “в документации сказано, что можно без заголовков, а так не работает” — нет. Для начала попробуйте отправить запрос через curl и посмотрите на результат.
Помните, что Postman — это всё-таки клиент, у которого есть свои навороты. Так что пусть он их накручивает сколько влезет, эти хидден-заголовки тестировать особо не надо. А вот послать хотя бы разок честный curl — надо!
Так что прячем hidden-заголовки и проверяем без них в этом пункте. Да, doregister без заголовков работает, всё ок.
Тело запроса (body)
Что мы тут тестируем:
Правильное тело (пример)
Различные параметры (обязательность, работа параметров)
Бизнес-логика
Ошибки: бизнес-логика
Перестановка мест слагаемых
Регистрозависимость
Ошибки: не well formed xml / json
Пункты 1-4 мы уже обсудили выше. Идем по ТЗ и каждую строчку изучаем и проверяем.
Перестановка мест слагаемых
Это как раз особенность API, поэтому очень важно её проверить. Бизнес-логика и проверки “а что можно ввести в такое-то поле” одинаковы для GUI и API, а вот переставить поля местами в графическом интерфейсе не получится.
При этом в API это сделать проще простого. Мы ведь передаем пары “ключ-значение”. Что будет, если мы попробуем поменять их местами?
В идеале ничего не случится, потому что принимающая система должна из запрос цеплять информацию именно по названию ключа, а не делать “select *” и потом говорить “для первого поля из запрос проверь то, для второго сделай это…”.
Ведь потом изменится входной запрос и у нас вся интеграция сломается! А это нехорошо… Так что смотрим как система реагирует на перестановки.
Регистрозависимость
Вы же помните о том, что регистронезависимость не появляется из воздуха? Её делает разработчик. Поэтому и проверить “как ведет себя система” — тоже надо. И в заголовках, и в теле, и в параметрах URL — вообще везде, где есть символы.
Ошибки в ответе от сервера
Всегда обязательно изучаем ошибки. Помимо ошибок в бизнес-логике есть ещё неправильно составленный запрос. То есть не well formed. Пробуем такой послать и смотрим на адекватность ошибки
См также:
Практика на примере Users
По бизнес-логике мы уже прошли, теперь пойдем по API-части:
1. Перестановка мест слагаемых
В json пробуем перестановку:
{
"name": " Машенька{{$randomInt}}",
"email": "test{{$randomInt}}@mail.com",
"password": "1"
}Ура, работает! А как насчет form-data? Тоже всё ок, это хорошо:

2. Регистрозависимость
Мы уже поняли, что в Users регистронезависимости может и не быть. Поэтому проверим на одном поле для начала. И не email, а то с ним может быть ложная уверенность в корректной ошибке:
{
"email": "test{{$randomInt}}@mail.com",
"NAME": " Машенька{{$randomInt}}",
"password": "1"
}Запрос не сработал, увы: "Параметр name является обязательным!"

Названия ключей регистрозависимы. Это не очень хорошо, хотя и некритично. Такой баг разработчик может не захотеть исправлять, “пусть присылают по документации”. Ну что же, тогда единственным аргументом будет потом количество обращений в поддержку.
Но мы, по крайней мере, получили информацию по работе системы.
3. Well formed
У нас на входе json, смотрим его правила:
Данные написаны в виде пар «ключ:значение»
Данные разделены запятыми
Объект находится внутри фигурных скобок {}
Массив — внутри квадратных []
И пытаемся сломать. Вообще самая частая ошибка — это запятая после последней пары «ключ:значение». Мы обычно скопипастим строку из середины (вместе с запятой), поставим в конец объекта, а запятую удалить забудем. Получится как-то так:
{
"email": "test{{$randomInt}}@mailcom",
"name": " Машенька{{$randomInt}}",
"password": "1",
}Отправляем такой запрос. М-м-м-м, ответ как-то не очень:

Это постман мне настойчиво подсвечивает красным лишнюю запятую, а если вызов идет из кода и там подсветки нет, то как понять, что пошло не так? Из текста сообщения об ошибке. Только вот из такого текста разработчик очень долго будет угадывать, что не понравилось системе… Нехорошо, стоит завести баг.
Попробуем другие способы сломать формат:
— не в виде пар “ключ:значение”
{
"email": "test{{$randomInt}}@mail.com",
"name": " Машенька{{$randomInt}}",
"password"
}Ответ будет такой же — "Параметр email является обязательным!"
Заметьте, что если мы “сломаем” так email, будет ложное ощущение, что система работает хорошо и правильно дает подсказку. А на самом деле нет…
Так что если уже замечали странности раньше, проверяем на другом поле — на пароле, а не емейле. И видим, что ошибка непонятная.
— данные не разделены запятыми
{
"email": "test{{$randomInt}}@mail.com"
"name": " Машенька{{$randomInt}}"
"password": "1"
}— объект в квадратных скобках, а не фигурных
[
"email": "test{{$randomInt}}@mail.com",
"name": " Машенька{{$randomInt}}",
"password": "1"
]Ответ везде одинаковый — "Параметр email является обязательным!"
Не очень хорошо, в ожидаемый результат чек-листа проверок мы запишем что-то более «правильное» =)) Например, ошибка 400 и сообщение "Не well formed json в запросе".
URL
Там тоже могут быть параметры. Обычно это в методе GET делается, прямо в параметры URL зашивается какая-то информация. Например, идентификатор элемента, который мы хотим получить.
Тестируем точно также, как если бы параметр был в теле:
Правильный параметр (из примера)
Обязательность (что, если параметр не указать?)
Бизнес-логика (тест-дизайн)
Регистрозависимость (если параметр текстовый)
Практика на примере JIRA
Почему не на примере Users? А потому что в методе doRegister нет параметров, которые передаются в URL. Да и вообще в Users их нету, там даже get через POST сделан, но сейчас не об этом…
Поищем примеры в Jira Cloud REST API. Например, метод «Get Issue», вот какой у него URL:
GET /rest/api/3/issue/{issueIdOrKey}Мы передаем в URL или id задачи, или её ключ. Условно говоря, это или что-то типа “13005” или “TEST-1”.
И вот тут мы уже можем развернуться!
Правильное значение
Базовый позитивный тест, что метод в целом работает. Вызываем обязательно и так, и так:
13005
TEST-1
Обязательность
Попробуем не передать параметр:
/rest/api/3/issue/
/rest/api/3/issueТест-дизайн
Тут стоит подумать в тему состояний объекта. Пробуем получить:
Свежесозданную задачу
Несколько раз измененную / отредактированную
Заполненную по минимуму / по максимуму
В разных статусах
Закрытую
Удаленную
Не существующую (такого номера ещё нет — это отличается от “он есть в базе, но задача была закрыта”)
Регистрозависимость
При передаче issueId этот пункт не проверить, цифры сами по себе регистронезависимы. Но если мы передаем задачу через Key, то это уже символы. Значит, проверка актуальна:
/rest/api/3/issue/test-1
/rest/api/3/issue/TEst-1Тип метода
Что будет, если мы “подменим” тип запроса?
POST → GET (совсем разные типы запросов)
POST → PUT (похожие типы)
Как система отреагирует? Она может или отработать “словно так и надо”, или выдать ошибку. И тут следим за тем, чтобы ошибка была внятной и понятной.
А ещё может показаться, что игнорирование ошибок пользователя — это хорошо. Но далеко не всегда. Например, у меня был случай, когда на проекте обновили библиотеку и она стала намного жестче с ошибкам интеграции. Тут то и выяснилось, что запросы исходные системы присылали “кто во что горазд”.
Если бы система сразу падала, то на первичной интеграции пришлось бы поднапрячься побольше, зато дальнейшие переходы были бы бесшовными. А когда уже всё в продакшене, это будет стопить обновление релиза. Так что может, лучше заранее начать ловить за руку “ты мне какой-то треш” шлешь?
Практика на примере Users
Меняем в запросе тип метода с POST на GET — а ему всё равно, успешно!

Нельзя сказать, что это прям вау-поведение, но для Users это нормально =)
Что тестируем в ответе
Тело ответа
Чек-лист проверки:
Какие поля вернулись в ответе?
Значения в полях
Текст ошибок
Поля в ответе нужно:
сравнить с ТЗ
сравнить между собой SOAP \ REST
Если у нас есть ТЗ — то всё понятно. Читаем, как должно быть, проверяем, как есть на самом деле. Смотрим на то, что все поля из требований вернулись, и что в них правильное значение. А то вдруг я сохраняю имя “Оля”, а там всегда сохраняется “Тестовый”... Очень удобно сразу автотесты писать в том же постмане, если отдельного фреймворка нет — идем по ТЗ и каждое поле выверяем.
Если ТЗ нет, то уже сложнее. Ищем «хранителя информации», расспрашиваем, проверяем, как работает на самом деле. Думаем, есть ли проблемы в текущем поведении. Нет? Ок, значит, так и надо.
Если в ответе сообщение об ошибке, то внимательно его изучаем. В API это ещё важнее, чем просто в графическом интерфейсе. Поймет ли пользователь, что именно он сделал не так, где именно ошибся? Помните, плохое сообщение об ошибке приведет к тому, что вас будут дергать по пустякам, вырывая из контекста.
См также:
Если у вас в системе два интерфейса — SOAP и REST, нужно проверить оба. Обычно они должны быть идентичны. Да и в коде это обеспечивается условно говоря двойной аннотацией “сделай и soap, и rest сгенери”, разработчик не дублирует всю функциональность дважды, а просто “включает” API.
В таком случае действительно всё будет работать идентично, кроме пустых полей в ответе. Что будет, если какое-то поле не заполнено? Может легко быть такая ситуация:
— SOAP возвращает пустые поля;
— REST нет.
Более того, это даже может быть нормально! Например, исходно писался только SOAP-интерфейс, и было правило возвращать все поля, даже пустые. Потом решили стать модными, молодежными, подключили REST. И решили там поля пустые не возвращать.
К тому же в SOAP всегда есть схема WSDL, где указаны обязательные поля. Значит, они будут возвращаться в ответе. В ресте же схема WADL необязательна, да и там любят придерживаться принципа минимальных чернил, лишнего не выводить.
В общем, проверьте обязательно, как методы срабатывают на:
Отсутствие данных на входе (поле не пришло вообще / пришло пустое)
Пустые поля на выходе
Если по разному, то это должно быть описано в доке!
Практика на примере Users
Сначала отправляем базовый запрос и там, и там, как в документации. Но уже по документации мы можем заметить, что набор поле в ответах разный. В SOAP перечислены все поля юзера, включая кличку кошечки, собачки итд… В REST же несколько базовых полей, и всё.
Как так вышло? Очень просто. Для реста набор полей согласовали, разработчик сделал. Потом я сказала, что хочу ещё и SOAP. А там нужна схема WSDL, разработчик с ней особо не парился. Есть сущность “user”? Ну её и вернем в ответе. А в сущности как раз много полей…
Мне не критично, так что менять не стали, да и вообще отличный пример «да, и так бывает» же! =))
Ок, давайте теперь посмотрим на особенности API, ведь всю бизнес-логику перетестировать в SOAP смысла нет, она должна совпадать… Ну разве что вы совсем не верите своим разработчикам… Или кейсы очень важные. А так — бизнес-логику смотрим один раз, а потом переходим в особенностям API.
Перестановка мест слагаемых
Поменяем местами name и email — ой ёй ёй!

Система пишет «Некоректный email Имечко 666». Это значит, что она ориентируется не названия полей, передаваемые в тегах, а на их порядковых номер. И это ОЧЕНЬ ПЛОХО, на такое стоит идти ставить баг.
Тем более обоснование у нас есть — неединообразно работает. REST вот от перестановки не зависит, и SOAP не должен.
А ещё слово «Некоректный» написано неправильно, там должно быть две буквы “р”. Проверяем в REST, посылая заведомо плохой емейл — да, и там ошибка. Надо бы исправить. Текстовку ошибок вычитываем внимательно!
Регистрозависимость
Каждый тег регистрозависим сам по себе — открывающий и закрывающий должны совпадать по написанию, в том числе по регистру. Если это сломать, будет точно плохой запрос, но мы начнем с условно хорошего — оба тега в капс-локе:
<EMAIL>ggg55555@mail.com</EMAIL>Работает!

А вот теперь попробуем разный регистр внутри тегов (в json такую проверку не сделать, это особенно XML, дублирование названия поля):
<EMAIL>ggg55555@mail.com</email>Не работает — Bad Request. Чтож, вполне логично.
Well formed XML
Что, если сломать XML? Скажем, оставить закрывающий тег «/email» без второй угловой скобки:
<wrap:doRegister>
<email>ggg5555@mail.com</email
<name>Имечко 666</name>
<password>1</password>
</wrap:doRegister>Возвращается ошибка
<faultcode>SOAP-ENV:Client</faultcode>
<faultstring>Bad Request</faultstring>Не супер информативно, но в целом ясно, что мы где-то с запросом накосячили. И если такой текст именно на well formed, то и ладно. Тогда по нему будет сразу понятно, в чем именно проблема. Посмотрим дальше.
Статус-коды
Разработчик может использовать стандартные коды ответов,
2хх — все хорошо
4хх — ошибка на клиенте (в запросе)
5хх — ошибка на сервере
А может придумать свои:
570 — пустой ответ на поиск;
571 — нашли одного ФЛ;
572 — нашли несколько ИП;
573 — нашли только ИП;
…
Разработчик может даже перекрыть стандартные:
400 — Bad Request
↓
400 — Internal Server Error
Но так лучше не делать =))) Просто знайте, что возможность такая имеется.
Если разработчик ленивый и не настроил коды, то вы будете огребать на любую ошибку стандартный код: 400 Bad Request. Неверный заголовок? Ошибка 400. Неверное тело? Ошибка 400. Проблемы в бизнес-логике? Ошибка 400… Ну и как тут разобраться, что именно надо исправлять?
Или ещё “лучше”, разработчик может сказать “всегда возвращай код 200”. И это очень нехорошо, ведь именно по коду мы ориентируемся в первую очередь: всё хорошо или что-то плохо?
Поэтому статус-код проверяем всегда, обращаем на него внимание. Ну а если в методе собственные статусы (как, например, в методе MagicSearch)
Практика на примере Users
На статус надо было обращать внимание всегда, чтобы не дублировать снова все тесты. Но сейчас просто дернем “хороший” и “плохой” запросы.
Хороший — статус 200, всё ок:

Плохой — ой, статус снова 200, хотя мы видим сообщение об ошибке:

Нехорошо! На это надо ставить баг.
Итоговый чек-лист проверки doRegister
Помним, что в первую очередь проверяем бизнес-логику. А потом уже всякие API-штучки, куда входят:
Регистрозависимость
Перестановка мест параметров
Well formed запрос
Базовый тест
Базовый тест тщательно выверяет каждое поле из “корректного” ответа. Проверяет, как вызов API-метода влияет на отображение в GUI… Поэтому его пропишем текстом, а остальные тесты соберем в табличку.
1. Проверка примера из ТЗ (но имя и емейл меняем на уникальные)
{
"email": "milli{{$randomInt}}@mail.ru",
"name": " Машенька{{$randomInt}}",
"password": "1"
}ОР:
1. Статус 200
2. В ответе следующий набор полей:
"name": " Машенька562", (то имя, что мы отправили)
"avatar": "http://users.bugred.ru//tmp/default_avatar.jpg", (в этом методе всегда такой урл стандартной аватарки)
"password": "4dff4ea340f0a823f15d3f4f01ab62eae0e5da579ccb851f8db9dfe84c58b2b37b89903a740e1ee172da793a6e79d560e5f7f9bd058a12a280433ed6fa46510a",
"birthday": 0,
"email": "milli754@mail.com", (тот емейл, мы мы отправили)
"gender": "",
"date_start": 0,
"hobby": ""3. Пользователь добавлен в общий список. Проверяем через GUI — http://users.bugred.ru/. Ищем поиском — есть!

Проверяем все поля:
Емейл правильный, какой мы отправляли.
Автор «rest», что логично.
Дата изменения — сегодня, что тоже правильно.
4. Под пользователем можно войти в систему — нажимаем “Войти”, вводим емейл из запроса, пароль из запроса, проверяем авторизацию.
Остальные тесты
Бизнес-логика из ТЗ |
|
Уникальный емейл, дубликат имени { "email": "milli{{$randomInt}}@mail.ru", "name": " Машенька562", "password": "1" } | ОР: Статус 400 В теле ошибка: "name (переданное имя) уже есть в базе" |
Уникальное имя, дубликат емейл { "email": "milli754@mail.ru", "name": " Машенька{{$randomInt}}", "password": "1" } | ОР: Статус 400 В теле ошибка: "email (переданный email) уже есть в базе" |
Дубликаты сразу имени и емейл { "email": "milli754@mail.ru", "name": " Машенька562", "password": "1" } | ОР: Статус 400 В теле ошибка: "email (переданный email) уже есть в базе" |
Параметр email |
|
Корректный существующий email, куда может прийти почта — подставляем свой (начинаем всегда с корректного) | Успешный запрос |
Верхний регистр, цифры в имени пользователя и доменной части — TEST77@mail9.ru | Успешный запрос |
Email с дефисами и нижним подчеркиванием — test_user-1@mail_test-1.com | Успешный запрос |
Email с точками в имени пользователя и парой точек в доменной части — test.user@test.test.test.ru | Успешный запрос |
Email без точек в доменной части — test@mailcom | Статус 400, ошибка «email некорректный» |
Превышение длины email (>320 символов) | Статус 400, ошибка «email некорректный» |
Отсутствие @ в email — testmail.ru | Статус 400, ошибка «email некорректный» |
Email с пробелами в имени пользователя — test user@mail.ru | Статус 400, ошибка «email некорректный» |
Email с пробелами в доменной части — test@ma il.ru | Статус 400, ошибка «email некорректный» |
Email без имени пользователя — @mail.ru | Статус 400, ошибка «email некорректный» |
Email без доменной части — test@ | Статус 400, ошибка «email некорректный» |
Некорректный домен первого уровня (допустимо 2-6 букв после точки: .ru) — test@mail.urururururu | Статус 400, ошибка «email некорректный» |
Параметр name |
|
Простое имя типа “Ольга” | Успешный запрос |
Разный регистр, буквы и спецсимволы: Mixa1234567890`-=[]\;’/.,~!@#$%^&*()_+}{:”?><|Ё_+ХЪ/ЖЭБЮ,ёхъ\-=. | Успешный запрос |
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест. | Успешный запрос |
1 000 000 символов — ищем технологическую границу | Ошибка 400 — «Имя слишком длинное. Максимальная длина (такая-то)» |
Параметр password |
|
Обычный пароль типа 1 | Успешный запрос |
Разный регистр, буквы и спецсимволы: Mixa1234567890`-=[]\;’/.,~!@#$%^&*()_+}{:”?><|Ё_+ХЪ/ЖЭБЮ,ёхъ\-=. | Успешный запрос |
1 000 символов — ищем верхнюю границу, если она есть. Заодно смотрим, как это выглядит в интерфейсе и корректируем тест. | Успешный запрос, пароль обрезается до X символов |
1 000 000 символов — ищем технологическую границу | Успешный запрос, пароль обрезается до X символов |
Тело сообщения (body) |
|
Перестановка мест слагаемых в json { "name": " Машенька{{$randomInt}}", "email": "test{{$randomInt}}@mail.com", "password": "1" } | Статус 200, корректный ответ |
Перестановка мест слагаемых в form-data | Статус 200, корректный ответ |
Меняем регистр у любого параметра: { "email": "test{{$randomInt}}@mail.com", "NAME": " Машенька{{$randomInt}}", "password": "1" } | Статус 200, корректный ответ |
Меняем в запросе тип метода с POST на GET | Статус 400, ошибка «Неправильный тип метода, нужно использовать POST» |
Well formed json |
|
Запятая после последней пары «ключ:значение»: { "email": "test{{$randomInt}}@mailcom", "name": " Машенька{{$randomInt}}", "password": "1", } | Статус 400 В теле ошибка: "Не well formed json в запросе" |
Запрос не в виде пар “ключ:значение”, у пароля убираем значение: { "email": "test{{$randomInt}}@mail.com", "name": " Машенька{{$randomInt}}", "password" } | Статус 400 В теле ошибка: "Не well formed json в запросе" |
Данные не разделены запятыми { "email": "test{{$randomInt}}@mail.com" "name": " Машенька{{$randomInt}}" "password": "1" } | Статус 400 В теле ошибка: "Не well formed json в запросе" |
объект в квадратных скобках, а не фигурных [ "email": "test{{$randomInt}}@mail.com", "name": " Машенька{{$randomInt}}", "password": "1" ] | Статус 400 В теле ошибка: "Не well formed json в запросе" |
Вывод
Тестирование API — это не страшно! По факту это всё то же самое, что в GUI + дополнительные тесты. В интерфейсе нельзя подвигать местами поля или изменить название поля. А в API можно.
Но всегда в первую очередь важен тест-дизайн. Прочитайте ТЗ и проверьте его, учитывая классы эквивалентности и граничные значения. А потом добавьте API-часть:
Перестановка мест слагаемых в json
Перестановка мест слагаемых в form-data
Регистрозависимость
Другой тип метода
Well formed json / xml
Ну а если что-то подзабудется, то можно открыть эту статью и свериться с чек-листом отсюда! =))
PS — статья написана в помощь студентам моих курсов «Инженер по тестированию ПО» и «Тестирование REST API». Хотите практики? Приходите к нам =)
Комментариев нет:
Отправить комментарий